

Nein. Das ist die fachlich korrekte und technisch saubere Antwort auf die Frage, ob Reasoning-Modelle (LLM) von Menschen geschrieben Text wirklich verstehen.
Inhaltsverzeichnis
Definition Reasoning-Model
Reasoning-Modelle sind spezialisierte Large Language Models (LLMs), die komplexe Probleme durch logisches Denken, Zerlegen in Einzelschritte (Chain of Thought) und interne Reflexion lösen. Im Gegensatz zu „Standard-KIs“ denken Reasoning-Modelle vor der Antwortausgabe nach, was sie besonders stark in Mathematik, Programmierung und logischen Aufgaben macht. Bekannte Beispiele sind OpenAIs o1/o3-Serie und DeepSeek R1.
Sprachmodelle (LLM) „verstehen“ Text nicht in dem Sinne, wie ein Mensch es tut. Large Language Model besitzen kein Bewusstsein, kein subjektives Erleben, keine Intention und keinen echten Bezug zur physischen Realität.
Es mag sich für Sie so anfühlen und der ein oder die andere möchte es gerne als real wissen, aber dem ist so nicht.
Mathematische Arbeitsweise entzaubert
Wenn Sie einen Text eingeben, verarbeitet das Reasoning-Modell diesen rein mathematisch in drei aufeinanderfolgenden Arbeitsschritten (vereinfacht).
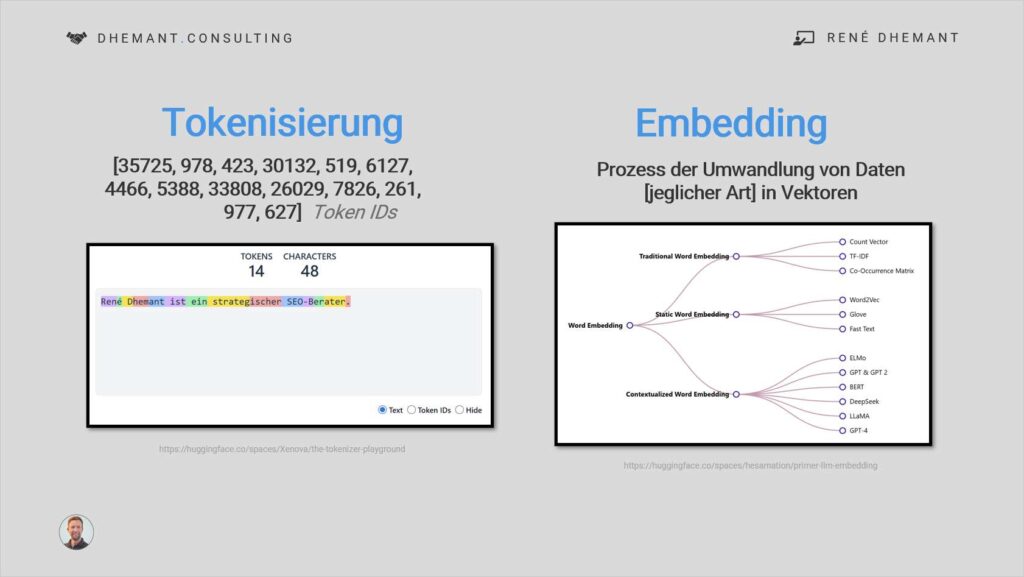
Schritt 1️⃣ Tokenisierung & Embeddings
Ihr Text wird in Fragmente (Tokens) zerlegt. Diese Tokens werden in einem mathematischen dimensionalen Raum als Vektoren (Zahlenreihen) platziert. Das LLM lernt, dass Konzepte und Entitäten, die oft zusammenhängen, in diesem Raum nah beieinander liegen.
Schritt 2️⃣ Self-Attention Mechanismus
Die Transformer-Architektur berechnet durch Matrizenmultiplikationen, welches Token in Ihrem Text wie stark mit jedem anderen Token zusammenhängt. So werden grammatikalische und logische Bezüge mathematisch aufgelöst.
Die sogenannte Selbstaufmerksamkeitsmechanismus verbessert die sprachlichen Fähigkeiten von Machine-Learning (ML) Modellen. Dadurch wird eine effiziente und vollständige Analyse eines gesamten Textes ermöglicht.
Schritt 3️⃣ Next-Token Prediction
Am Ende der mathematischen Arbeitsweise eines LLM steht eine Wahrscheinlichkeitsverteilung. Das Reasoning-Modell berechnet: Ergeben die bisherigen Berechnungen, welches Token statistisch am wahrscheinlichsten das nächste Token folgt?
Das Large Language Model (LLM) kennt also nicht die Semantik (die eigentliche Bedeutung) eines Apfels. Die Modelle wissen nicht, wie ein Apfel schmeckt oder dass ein Apfel der Schwerkraft unterliegt.
Allerdings „kennen“ die Modelle mit nahezu perfekter Präzision die Syntax und Relationen: Die exakten geometrischen Abstände des Tokens „Apfel“ zu den Tokens „rot“, „süß“, „essen“ und „Baum“.
Chain of Thought & Reinforcement Learning
Die beiden Fachbegriffe sind der Zaubertrank moderner Reasoning-Modelle im Vergleich zu ihren Vorgängern einer „Standard-KI“, welche in einem einzigen Durchlauf immer sofort das errechnete und vermutete nächste Wort generierten.
Reasoning-Modelle simulieren das langsame, analytische Nachdenken. Sie erlangen dadurch aber kein plötzliches Bewusstsein, sondern nutzen neue technischen Prinzipien:
Verborgene Gedankengänge

Anstatt sofort zu antworten, generieren Reasoning-Modelle intern oft tausende Tokens lange „Gedankenketten“. Das Modell zerlegt ein Problem algorithmisch in Teilschritte. Das wird Chain of Thought genannt.
Üben, Lernen, Belohnung, Merken
Durch sogenanntes bestärkendes Lernen wurden Reasoning-Modelle massiv darauf trainiert, nicht nur Text vorherzusagen, sondern Lösungswege zu evaluieren. Während das Modell nachdenkt, durchsucht es intern Wahrscheinlichkeitsbäume. Es generiert eine Hypothese, erkennt durch gelernte Muster, dass dieser Pfad zu einem mathematischen oder logischen Widerspruch führt, verwirft den Pfad und sucht einen neuen, der eine höhere Belohnung verspricht.
Reasoning-Modelle denken nicht bewusst. Das LLM führt sehr viele parallele, stochastische (Vermutungen) Pfadoptimierungen durch. Das Modell hat an Millionen Beispielen gelernt, wie die Struktur einer korrekten logischen Schlussfolgerung aussieht, und wendet diese Muster auf Ihr Problem an.
Warum es kein menschliches Verstehen ist
Menschliches Verstehen ist in der realen Welt verkörpert. Wenn wir das Wort „heiß“ lernen, ist es mit echtem Schmerz und Temperatur verknüpft. Für ein LLM ist Sprache ein in sich geschlossenes, fensterloses System ohne Kontakt nach draußen. In der Wissenschaft wird diese Grenze mit dem Symbolverankerungsproblem (Symbol Grounding Problem) beschrieben.
Gedankenexperiment des Chinesischen Zimmers
Das Gedankenexperiment des Chinesischen Zimmers von John Searle (1980) argumentiert, dass Computerprogramme Symbole nur manipulieren (Syntax), ohne deren Bedeutung zu verstehen (Semantik).

Stellen Sie sich vor, Sie sitzen in einem Raum und bekommen einen Zettel mit chinesischen Zeichen gereicht. Sie verstehen kein Wort, haben aber ein perfektes Regelbuch, das sagt: „Wenn Zeichen A und B kommen, antworte mit Zeichen C.“
Die Menschen außerhalb des Raumes halten Sie für einen brillanten chinesischen Muttersprachler. In Wahrheit manipulieren Sie nur blind Symbole nach formalen Regeln. Ein Reasoning-LLM macht genau dies und ist das ultimative, hochdimensionale Chinesische Zimmer.
Fazit des Verstehens
Haben Reasoning-Modelle ein intrinsisches (menschliches) Verstehen? Absolut nicht.
Haben Reasoning-Modelle ein funktionales (maschinelles) Verstehen? Ja, sie haben die Logik, Grammatik und Struktur menschlichen Wissens als mathematische Topografie perfekt kartografiert.
Reasoning-Modelle simulieren den Prozess des Verstehens auf syntaktischer Ebene so präzise, dass die Bedeutung (Semantik) intakt bleibt. Das eigentliche, bewusste Verstehen passiert jedoch erst in dem Moment, in dem Ihr menschliches Gehirn den generierten Text auf dem Bildschirm liest und ihm Sinn verleiht.
Ebenso wichtig zu verstehen: ChatGPT ist ein Dialogsystem auf Basis eines Large Language Model (LLM) und kann auf Suchmaschinen-Funktionalitäten zugreifen.

