


Ein strategischer Leitfaden für die Interaktion von Menschen mit LLM-RAG-Systemen.
Die neue Suchlandschaft: Konversations-KI im Fokus
Die digitale Landschaft befindet sich in einem tiefgreifenden Wandel, der über die traditionelle schlüsselwortbasierte Suche hinausgeht und sich hin zu konversationsorientierten, KI-gesteuerten Interaktionen entwickelt. Diese Transformation erfordert ein grundlegendes Umdenken in der Art und Weise, wie Inhalte für die Online-Sichtbarkeit erstellt und optimiert werden.
Inhaltsverzeichnis
Die Evolution von Schlüsselwörtern zu Anfragen in natürlicher Sprache
Die digitale Landschaft erlebt eine bemerkenswerte Verschiebung: Nutzer bewegen sich von einfachen Schlüsselwortabfragen hin zu komplexeren, konversationsorientierten Suchanfragen. Diese Entwicklung, die sich seit der Einführung von benutzerorientierten Large Language Models (LLMs) Ende 2022 beschleunigt hat, ist tiefgreifend. Nutzer erwarten zunehmend, dass Suchmaschinen und KI-Tools nuancierte Fragen verstehen und umfassende Antworten liefern, anstatt nur eine Liste von Links anzuzeigen.
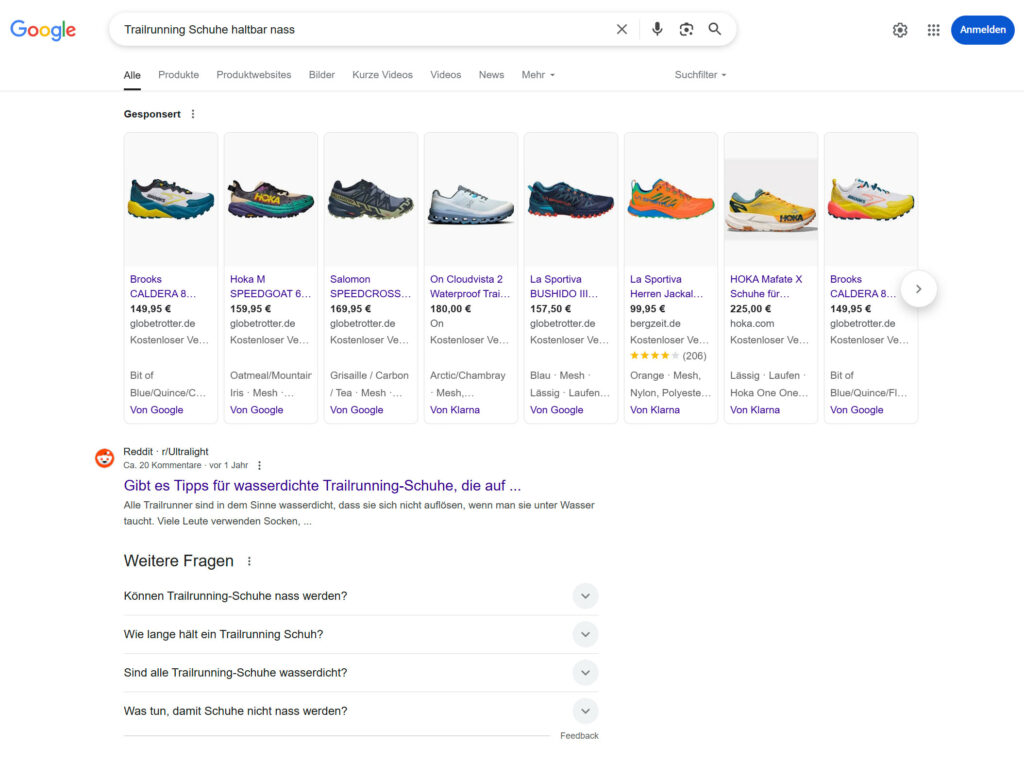
Diese Entwicklung ist nicht nur ein technologisches Upgrade; sie spiegelt ein tieferes Nutzerbedürfnis nach Effizienz und direkten Antworten wider. Traditionelle Suchmethoden erforderten von den Nutzern, Suchergebnisse zu interpretieren und Informationen selbst zu synthetisieren.
LLMs hingegen bieten direkte Antworten, was die kognitive Belastung reduziert und die benötigte Zeit für die Informationsbeschaffung verkürzt. Dies führt zu einer „Zero-Click“-Realität, in der die Informationsaufnahme oft direkt innerhalb der KI-Plattform oder der Google Suchergebnisseite stattfindet, ohne dass ein Klick auf eine Website erforderlich ist.
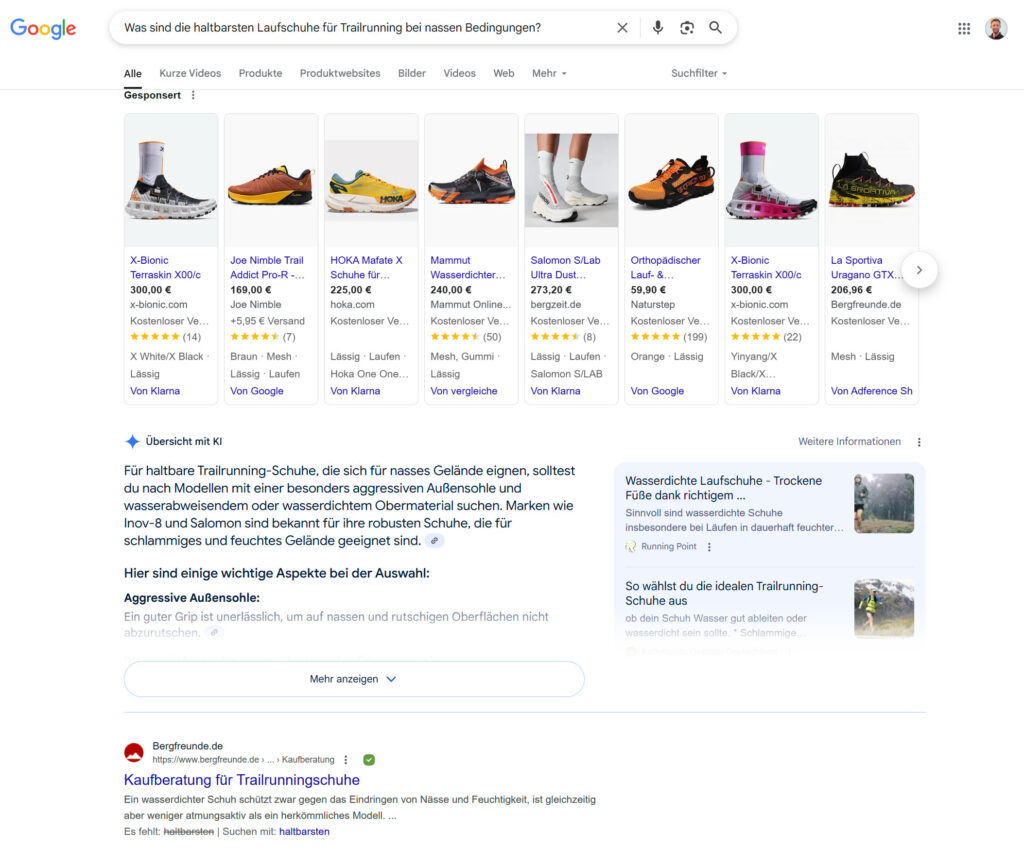
Für Unternehmen bedeutet dies, dass sich der Fokus von der reinen Generierung von Klicks hin zur Bereitstellung von Lösungen verlagert. Die Veränderung des Nutzerverhaltens – hin zu komplexeren, konversationsorientierten Anfragen – macht eine Neuausrichtung der Content-Strategie unerlässlich.
Wenn Nutzer vollständige Fragen stellen, müssen Inhalte so strukturiert sein, dass sie direkte, umfassende Antworten liefern und nicht nur schlüsselwortoptimierte Snippets oder Textfragmente. Dies erfordert eine Konzentration auf die Absicht des Nutzers und die Antizipation von Folgefragen.
Der Inhalt muss daher robuster sein und Themen in der Tiefe behandeln, um komplexe Anfragen vollständig zu beantworten.
Verständnis von Large Language Models (LLMs)
Large Language Models (LLMs) sind fortschrittliche Deep-Learning-Architekturen, die oft auf dem von Google im Jahr 2017 entwickelten Transformer-Modell basieren.
Sie werden auf riesigen Datenmengen trainiert, die Milliarden von Texten und anderen Inhalten umfassen, um Text und andere Inhalte zu generieren, zu übersetzen und verschiedene Aufgaben der natürlichen Sprachverarbeitung (NLP) zu bewältigen.
LLMs lernen Muster und Verbindungen innerhalb dieser Daten, anstatt Texte wie eine Datenbank zu speichern. Zu den wichtigsten Trainingsdatenquellen gehören öffentlich verfügbare Informationen aus dem Internet, kommerziell lizenzierte Datensätze sowie von Nutzern und Crowdworkern bereitgestellte Daten.
commoncrawl.org maintains a free, open repository of web crawl data that can be used by anyone.
Verständnis von Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG)-Systeme sind eine entscheidende Komponente für Unternehmensanwendungen. Sie rufen relevante Kontexte aus externen, verifizierten Wissensquellen ab, um die Antworten von LLMs zu erweitern.
Diese Architektur reduziert Halluzinationen (generierte, aber falsche Informationen) erheblich und verbessert die faktische Genauigkeit, indem sie Antworten auf spezifische, vertrauenswürdige Daten stützt.
LLMs, trotz ihrer riesigen Trainingsdaten, haben eine Wissensgrenze und können „halluzinieren“. RAG adressiert diese Einschränkung direkt. LLMs lernen allgemeine Muster aus massiven Datensätzen, speichern Fakten jedoch nicht wie eine Datenbank.
Dies bedeutet, dass ihr Wissen statistisch ist und veraltet oder ungenau sein kann. RAG überbrückt diese Lücke, indem es Echtzeit- und verifizierte Informationen bereitstellt, wodurch LLMs für spezifische, faktische Anfragen zuverlässiger werden.

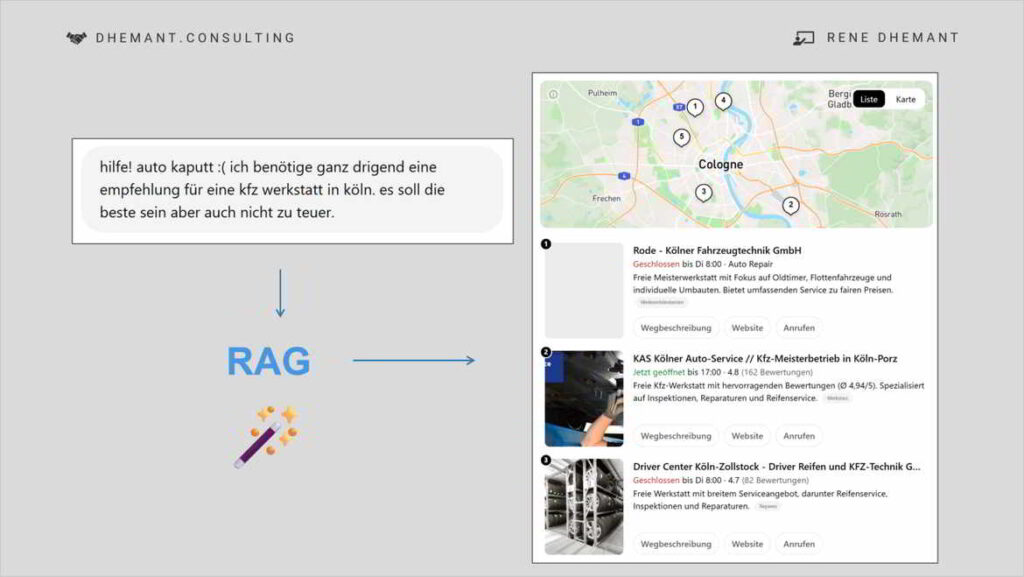
Die Optimierung für RAG ist daher für Unternehmen von größter Bedeutung, da sie sicherstellt, dass ihre spezifischen, genauen Informationen verwendet werden. Die Effektivität von RAG hängt vollständig von der Qualität und Zugänglichkeit der externen Daten ab, die es abruft.
Wenn RAG-Systeme auf externe Quellen zugreifen, müssen diese Quellen von hoher Qualität, strukturiert und leicht abrufbar sein.
Dies erhöht die Bedeutung des eigenen Website-Inhalts einer Marke und ihrer technischen Grundlage als die primäre Quelle der Wahrheit für RAG-Systeme. (Stichwort: Zitierfähigkeit)
Daten von schlechter Qualität oder unzugängliche Daten führen zu einer schlechten RAG-Leistung, unabhängig von den Fähigkeiten des LLM.
Die zentrale Rolle von Knowledge Graphs in der KI-gesteuerten Suche
Knowledge Graphs (KGs) sind Wissensbasen, die ein graphenstrukturiertes Datenmodell oder eine Topologie verwenden, um Daten darzustellen und zu verarbeiten.
Sie speichern miteinander verknüpfte Beschreibungen von Entitäten – Objekten, Ereignissen, Situationen oder abstrakten Konzepten – und kodieren gleichzeitig die freiformatigen Semantiken oder Beziehungen, die diesen Entitäten zugrunde liegen.
KGs werden von großen Suchmaschinen wie Google und Bing sowie von Frage-Antwort-Diensten wie Siri und Alexa verwendet.
Googles Knowledge Graph beispielsweise ist auf 5 Milliarden Entitäten und 500 Milliarden Fakten angewachsen.
Knowledge Graphs (KGs) bieten Kontext und Tiefe, wodurch KI-Systeme in der Lage sind, Daten zu schließen und neues Wissen abzuleiten.
Dies ermöglicht einen Übergang von der einfachen Schlüsselwortübereinstimmung zu einem semantischen Verständnis. KGs sind entscheidend für die Entitätserkennung und das Verständnis der Bedeutung hinter Suchanfragen.
Knowledge Graphs (KGs) stellen das semantische Rückgrat für LLMs dar, indem sie das strukturierte, relationale Verständnis liefern, das LLMs benötigen, um über statistische Wortmuster hinaus zu echtem Verständnis zu gelangen.
Während LLMs hervorragend in der Sprachgenerierung sind, liefern KGs die faktische, relationale Grundwahrheit, die genaue Antworten untermauert.
Dies bedeutet, dass eine Marke, um von LLMs genau dargestellt und zitiert zu werden, als klar definierte Entität in Knowledge Graphs, ob öffentlich (Wikidata, Google) oder dritten Datenquellen, existieren muss.
Die Verbindung zwischen strukturierten Daten mittels schema.org-Markup und Knowledge Graphs ist direkt: Das Vokabular schema.org hilft, KGs zu füttern.
Eine proaktive Entitätsverwaltung ist somit ein neues SEO-Gebot. Marken müssen ihre Präsenz in Knowledge Graphs aktiv verwalten, um eine genaue Darstellung sicherzustellen und die KI-Sichtbarkeit zu maximieren.
Googles Knowledge Graph wird automatisch generiert, kann aber beeinflusst werden. Das Erlangen eines Knowledge Panels (einer visuellen Darstellung eines KG-Eintrags) erfordert eine starke Online-Präsenz, strukturierte Daten und Bestätigung durch maßgebliche Quellen.

Dies bedeutet, dass Entitäts-SEO nicht länger optional ist; es ist eine Kernkomponente der LLM-Optimierung, die sicherstellt, dass LLMs eine Marke korrekt mit ihren Produkten, Dienstleistungen und Fachkenntnissen identifizieren und assoziieren.
Zusammenfassung
SEO-Berater René Dhemant erörtert die tiefgreifende Veränderung der SEO-Landschaft, die durch konversationelle KI-Systeme vorangetrieben wird.
René Dhemant zeigt, wie Large Language Models (LLMs) und Retrieval Augmented Generation (RAG)-Systeme die Art und Weise neu definieren, wie Nutzer suchen und Inhalte konsumieren, nämlich weg von schlüsselwortbasierten Anfragen hin zu natürlicher Sprache.
Als Strategieberater für profitorientierte Unternehmen betont René Dhemant die zentrale Rolle von Knowledge Graphs und strukturierten Daten bei der Sicherstellung, dass Marken von KI-Systemen korrekt verstanden und zitiert werden.
Die Notwendigkeit von „Entitäts-SEO“ und die Bedeutung von E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) für die Optimierung der eigenen Textinhalten ist unerlässlich, um in der KI-gesteuerten Suche als Marke hervorgehoben zu werden.
Rene Dhemant arbeitet als unabhängiger strategischer und technischer SEO-Berater in ganz Europa, wobei er seine SEO-Kenntnisse auf Führungsebene für die größeren Akteure auf dem Markt einsetzt.
Fazit
- Inhalte müssen personalisierter und relevanter werden
- Suchmaschinenoptimierung entwickelt sich weiter
- technische & strategische SEO-Expertise ist unerlässlich

Über den Autor René Dhemant
Der Autor René Dhemant ist strategischer SEO-Berater und Gründer der DHEMANT Consulting GmbH. Mit über 15 Jahren Erfahrung in der Suchmaschinenoptimierung unterstützt er Unternehmen strategisch. Sein Ziel ist es, digitale Sichtbarkeit aufzubauen und Marken nachhaltig im Wettbewerbsumfeld zu positionieren.
Als Speaker, Autor und Berater teilt René Dhemant sein Wissen auf SEO-Konferenzen, in Fachpublikationen und SEO-Workshops. Er vermittelt sein umfangreiches Know-how stets praxisnah und verständlich. Seine Inhalte orientieren sich dabei immer am aktuellen Puls und den neuesten Entwicklungen der digitalen Welt.
René Dhemant kann als strategischer SEO-Berater oder Speaker gebucht werden. Er bietet Unternehmen fundierte Unterstützung bei komplexen SEO-Herausforderungen und liefert auf Veranstaltungen wertvolle Einblicke in aktuelle Digitalstrategien.

FAQ SEO & KI-Suche
Was ist die Hauptänderung in der digitalen Suchlandschaft, die durch Konversations-KI verursacht wird?
Die digitale Suchlandschaft verändert sich grundlegend von der traditionellen schlüsselwortbasierten Suche hin zu konversationsorientierten, KI-gesteuerten Interaktionen. Nutzer stellen zunehmend komplexere Fragen in natürlicher Sprache und erwarten umfassende, direkte Antworten von Suchmaschinen und KI-Tools, anstatt nur eine Liste von Links zu erhalten. Dies führt zu einer Zero-Click-Realität, bei der die Informationsaufnahme oft direkt innerhalb der KI-Plattform erfolgt. Für Unternehmen bedeutet dies, dass sich der Fokus von der reinen Generierung von Klicks zur Bereitstellung von Lösungen und direkten Antworten verlagert.
Welche Rolle spielen Large Language Models (LLMs) und Retrieval Augmented Generation (RAG) in der Konversationssuche?
Large Language Models (LLMs) sind fortschrittliche KI-Modelle, die auf riesigen Datenmengen trainiert werden, um Text und andere Inhalte zu verstehen und zu generieren. Sie lernen Muster und Verbindungen in diesen Daten, speichern aber Fakten nicht wie eine Datenbank. RAG-Systeme erweitern die Fähigkeiten von LLMs, indem sie relevante Informationen aus externen, verifizierten Wissensquellen abrufen, um die Genauigkeit und Faktizität der Antworten zu verbessern und Halluzinationen zu reduzieren. Die Effektivität von RAG hängt stark von der Qualität und Zugänglichkeit der externen Daten ab.
Warum sind Knowledge Graphs (KGs) wichtig für die KI-gesteuerte Suche?
Knowledge Graphs (KGs) sind Wissensbasen, die Entitäten (Objekte, Ereignisse, Konzepte) und ihre Beziehungen zueinander in einer Graphenstruktur darstellen. Sie liefern den semantischen Kontext und die faktische Grundwahrheit, die LLMs benötigen, um über statistische Muster hinaus zu echtem Verständnis zu gelangen. KGs sind entscheidend für die Entitätserkennung und das Verständnis der Bedeutung hinter Suchanfragen. Für Marken ist es unerlässlich, als klar definierte Entität in Knowledge Graphs zu existieren und ihre Präsenz aktiv zu verwalten – Stichwort Entitäts-SEO, um von LLMs genau dargestellt und zitiert zu werden.
Wie helfen strukturierte Daten und schema.org-Markup bei der Optimierung von Landingpages für LLMs?
Strukturierte Daten, insbesondere schema.org-Markup, bieten maschinenlesbare Informationen über Inhalte, die es Suchmaschinen und LLMs erleichtern, den Inhalt zu verstehen, zu kategorisieren und zu interpretieren. Es wandelt Informationen in einen verbundenen Datengraphen um. Für LLMs mit RAG-Systemen ist Schema.org ein direkter Kommunikationskanal, der es ermöglicht, präzise und faktische Informationen abzurufen, was Halluzinationen entgegenwirkt. Eine systematische und konsistente Implementierung von Schema.org, einschließlich der Verwendung eindeutiger @ids für Entitäten, ist entscheidend für den Aufbau eines internen Knowledge Graphs, den LLMs nutzen können.
Was bedeutet E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) im Kontext der LLM-Optimierung?
E-E-A-T ist ein entscheidender Faktor für die LLM-Optimierung, da es als Stellvertreter für Vertrauenssignale für KI-Systeme dient. LLMs neigen dazu, Inhalte zu priorisieren, die Anzeichen von Erfahrung, Fachwissen, Autorität und Vertrauenswürdigkeit aufweisen. Dies wird durch Faktoren wie Expertenautoren, das Zitieren glaubwürdiger Quellen, die Demonstration direkter Erfahrung und die Konsistenz der Informationen über verschiedene Quellen hinweg signalisiert. Hochwertige, E-E-A-T-gesteuerte Inhalte, insbesondere solche mit Originalität und einzigartigen Einblicken, werden eher von KI-Systemen zitiert oder zusammengefasst.

