


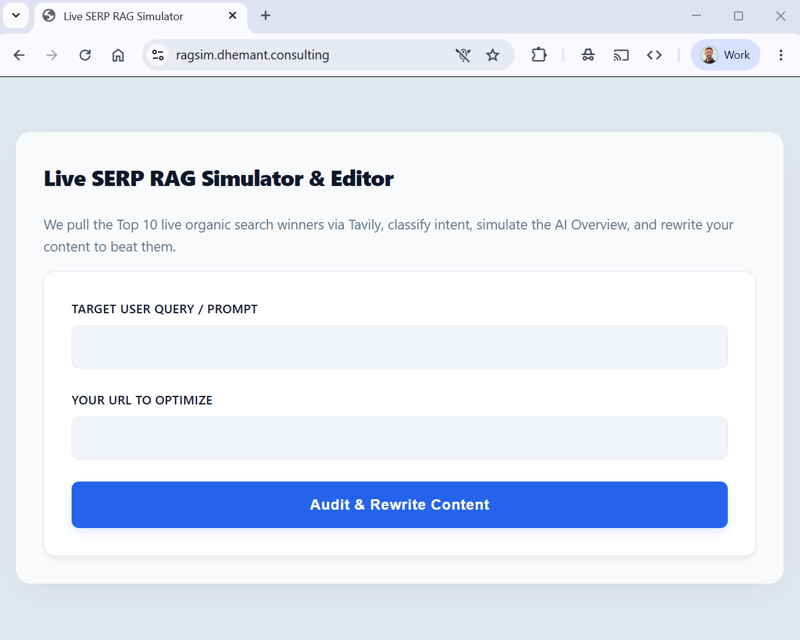
Moderne KI-Systeme wie Perplexity oder ChatGPT nutzen eine RAG-Architektur (Retrieval-Augmented Generation), um externe Datenquellen zu erschließen. Während die finale Textgenerierung durch das LLM probabilistisch erfolgt, basiert die vorgelagerte Informationsbeschaffung (Retrieval) auf deterministischen Prozessen. Erfahren Sie, wie sich dieser Ablauf durch Reverse Engineering transparent machen lässt, und auditieren Sie Ihre eigenen URLs mit meinem Open-Source RAG-Simulator.
Inhaltsverzeichnis
Die Kernhypothese: Deterministik in RAG-Pipelines

Genau genommen ist das RAG-Framework eine Architektur, die zwei separate Systeme miteinander verheiratet: Die RAG-Pipeline (Retrieval & Augmentation) und das generative LLM (Generation).
Die RAG-Pipeline ist dafür verantwortlich, Daten zu beschaffen, zu filtern und algorithmisch zu gewichten, um sie als hochrelevante Text-Chunks bereitzustellen. Erst im allerletzten Schritt werden diese Chunks an das generative LLM übergeben, welches auf dieser Basis die eigentliche Antwortsynthese durchführt.
Während die finale Text-Synthesis des LLMs auf probabilistischen Modellen (Varianzen) basiert, ist die vorangestellte RAG-Pipeline grundlegend deterministisch. Sie basiert auf Vektormathematik, semantischer Distanz und striktem Filtering.
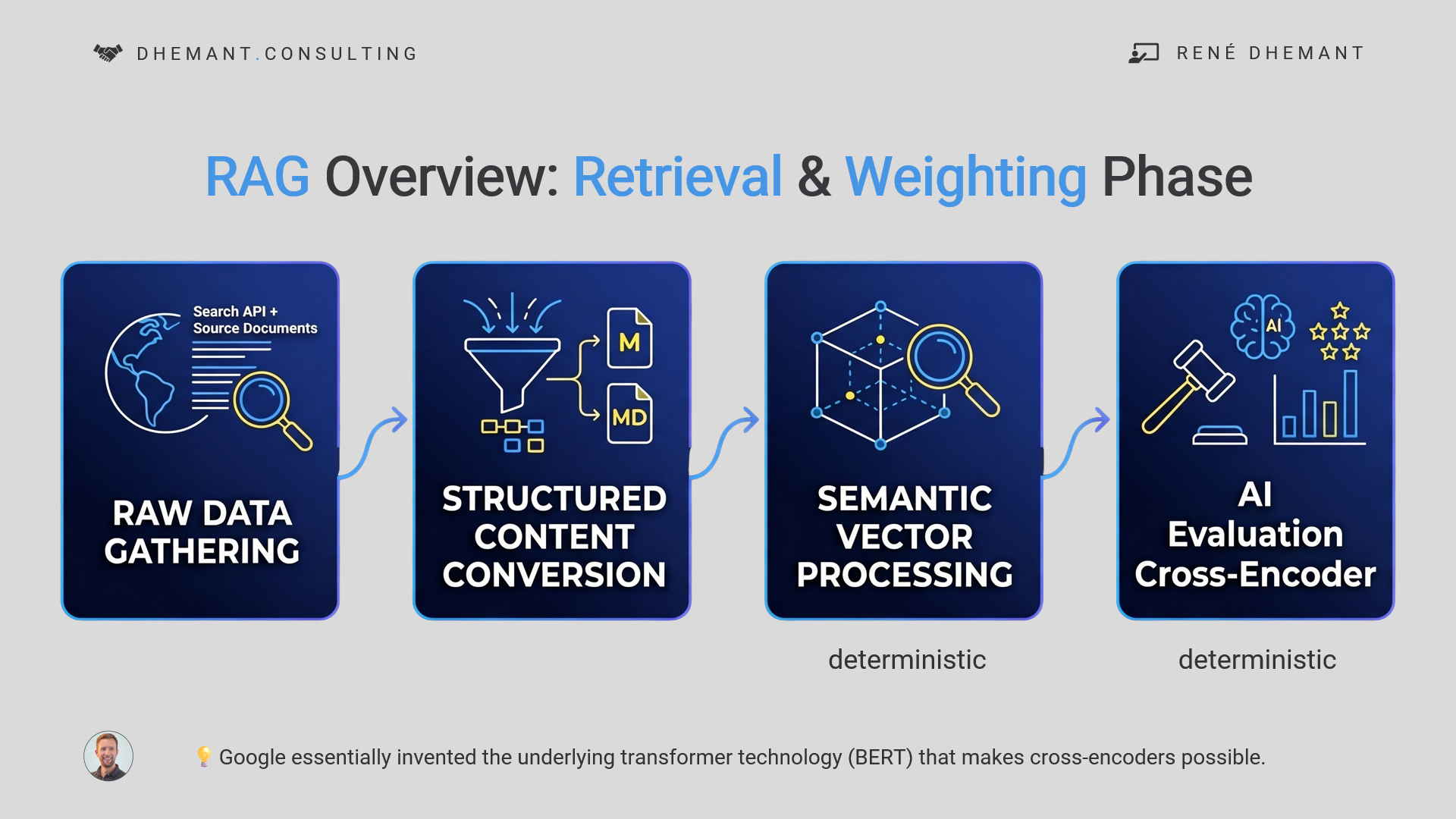
Die Hypothese: Da das Retrieval und die Gewichtung von Data Chunks vor der Übergabe an das LLM deterministisch ablaufen, unterliegen sie klaren mathematischen Regeln. Folglich kann diese Phase systematisch gemessen und optimiert werden.
Wenn wir in der Lage sind, die Auswahlkriterien für das Context Window zu verstehen, sind wir in der Lage, Content so zu strukturieren, dass er diese Slots mathematisch gewinnt und die finale Citation (Quellenangabe) sichert.
Hintergrund: 🎙️Premiere auf dem Tech SEO Summit 2026 von Audisto
Ich habe diese Hypothese und das eigens dafür entwickelte RAG Simulator-Tool erstmals auf dem Tech SEO Summit 2026 der Öffentlichkeit präsentiert.

Unter dem Titel „Reverse-Engineering the RAG Black Box: Architecting Content for AI Answer Engines„ haben wir gemeinsam unter die Haube moderner KI-Antwortsysteme geschaut.

Die Kernbotschaft meines Talks: Es ist an der Zeit aufzuhören, ChatGPT & Co. als unberechenbare Blackboxes zu behandeln. Wer die deterministische Retrieval-Phase versteht und sich tief in Konzepte wie Parent-Child Chunking, HyDE-Vektoren und Cross-Encoder Re-Ranking einarbeitet, kann seinen Content systematisch so strukturieren , dass er den begehrten „Share of Context“ mathematisch dominiert.

Die Methodik: Ein RAG Pipeline Simulator Tool
Um diese Hypothese mit realen Daten zu testen und potenzielle Optimierungsparameter zu evaluieren, habe ich ein RAG Pipeline Simulator Tool entwickelt und auf GitHub veröffentlicht.
Das Ziel ist es, den Simulator mit Live-SERP-Daten zu füttern, diese durch einen standardisierten, mehrstufigen AI-Retrieval-Prozess laufen zu lassen und die mathematischen Ergebnisse zu beobachten. Indem wir die Mechanik der Datengewichtung offenlegen, wechseln wir von stochastischem Raten zu einer Retrieval-Augmented Generation Assessment (RAGAS).
RAGAS (Retrieval-Augmented Generation Assessment) ist ein Open-Source-Framework, das speziell für die Bewertung und Optimierung von RAG-Systemen entwickelt wurde. Während herkömmliche Metriken (wie BLEU oder ROUGE) lediglich die Textähnlichkeit prüfen, nutzt RAGAS ein LLM als „Richter“ (LLM-as-a-Judge), um die Qualität der Pipeline auf tieferer Ebene zu messen.
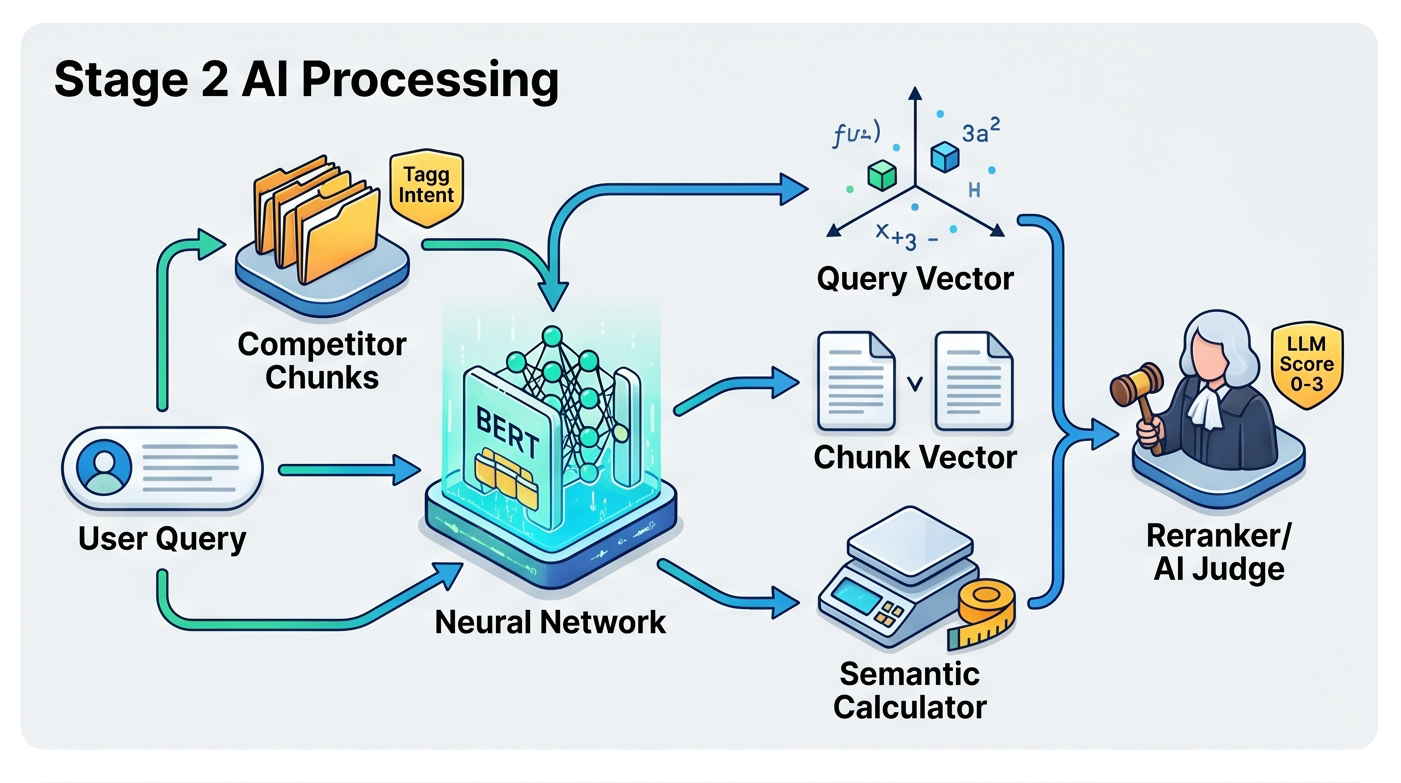
Der RAG-Simulator: Eine 10-stufige Architektur
Um die Hypothese greifbar zu machen, habe ich die technische Kernsequenz einer modernen, produktionstauglichen RAG-Pipeline nachgebaut.
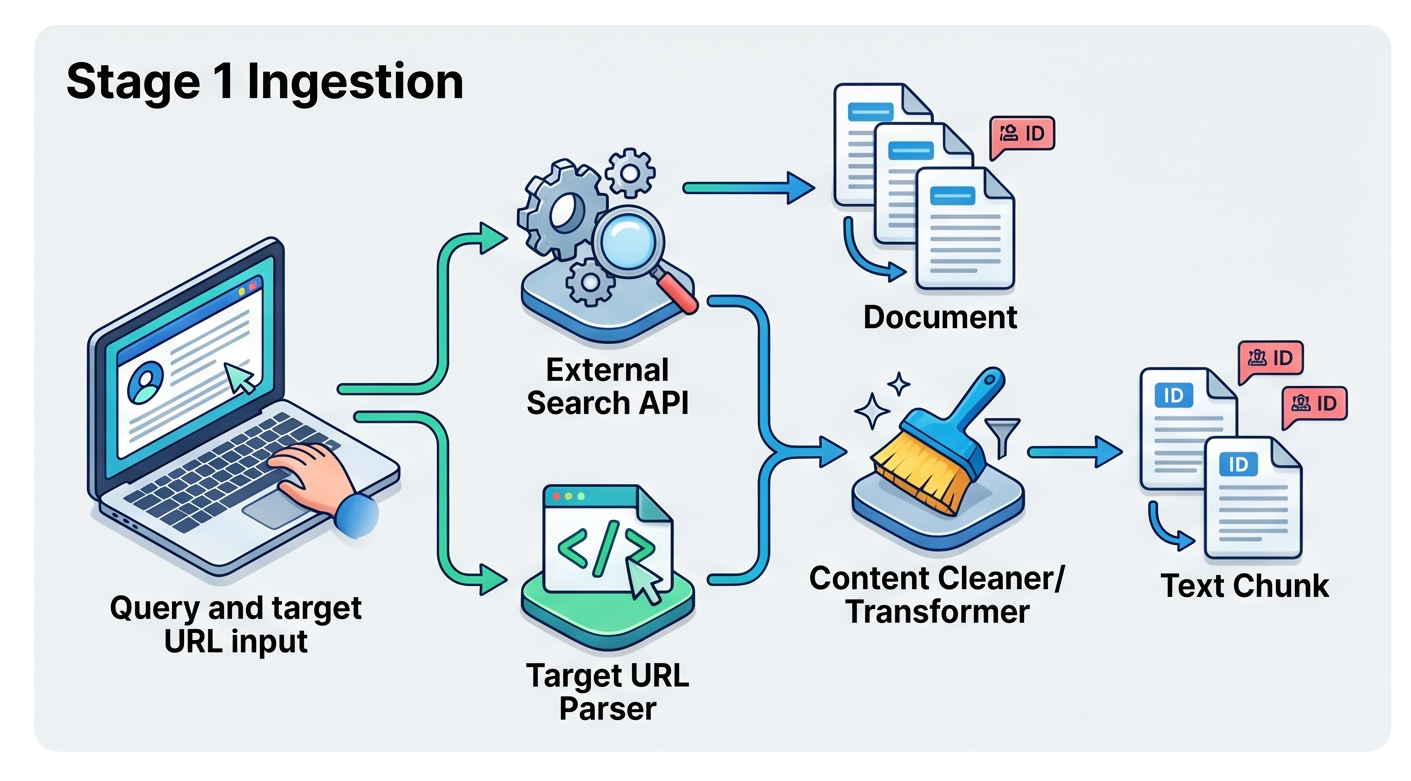
- Concurrent Data Ingestion
Das System benötigt Rohdaten. Es ruft parallel die Target-URL des Nutzers (den zu optimierenden Content) sowie die Live-Top-10 der organischen SERP-Wettbewerber für die jeweilige Suchanfrage (User-Prompt) ab. - Content Extraction & Parsing
Rohes HTML ist voller DOM-Noise (Navigation, Footer, Scripts). Der Scraper bereinigt diese Architektur, um ausschließlich den textlichen Kern-Content zu extrahieren, und mappt diesen in ein strukturiertes Format inklusive relativer Positionierung der Textblöcke. - Smart Text Chunking (Parent/Child)
Large Language Models (LLMs) leiden unter „Vector Blur“ (semantischer Verwässerung), wenn sie mit ganzen Webseiten gefüttert werden. Der geparste Text wird in verschachtelte semantische Blöcke (1000-Token Parent Chunks und 200-Token Child Chunks) separiert, um mikroskopische mathematische Präzision beim Retrieval zu erhalten, ohne den Makro-Kontext zu verlieren. - SERP Intent Classification
Vor der Evaluierung analysiert das System die extrahierten Wettbewerber-URLs, um die probabilistische Suchintention zu klassifizieren (z. B. Listicle, Guide, Vendor Page). Dies etabliert den grundlegenden Consensus der Suchanfrage und dient später als strenger Filter. - Dual HyDE & Semantic Vector Generation (Bi-Encoder)
Anstatt einfach den kurzen User-Prompt zu vektorisieren, nutzt das System Hypothetical Document Embeddings (HyDE). Es generiert vorab eine „Neutral Consensus“- und eine „Edge-Case Expert“-Antwort. Diese hypothetischen Ideal-Texte, sowie alle extrahierten Chunks, werden anschließend in mathematische Vektoren übersetzt. - Deterministic Semantic Search & Filtering
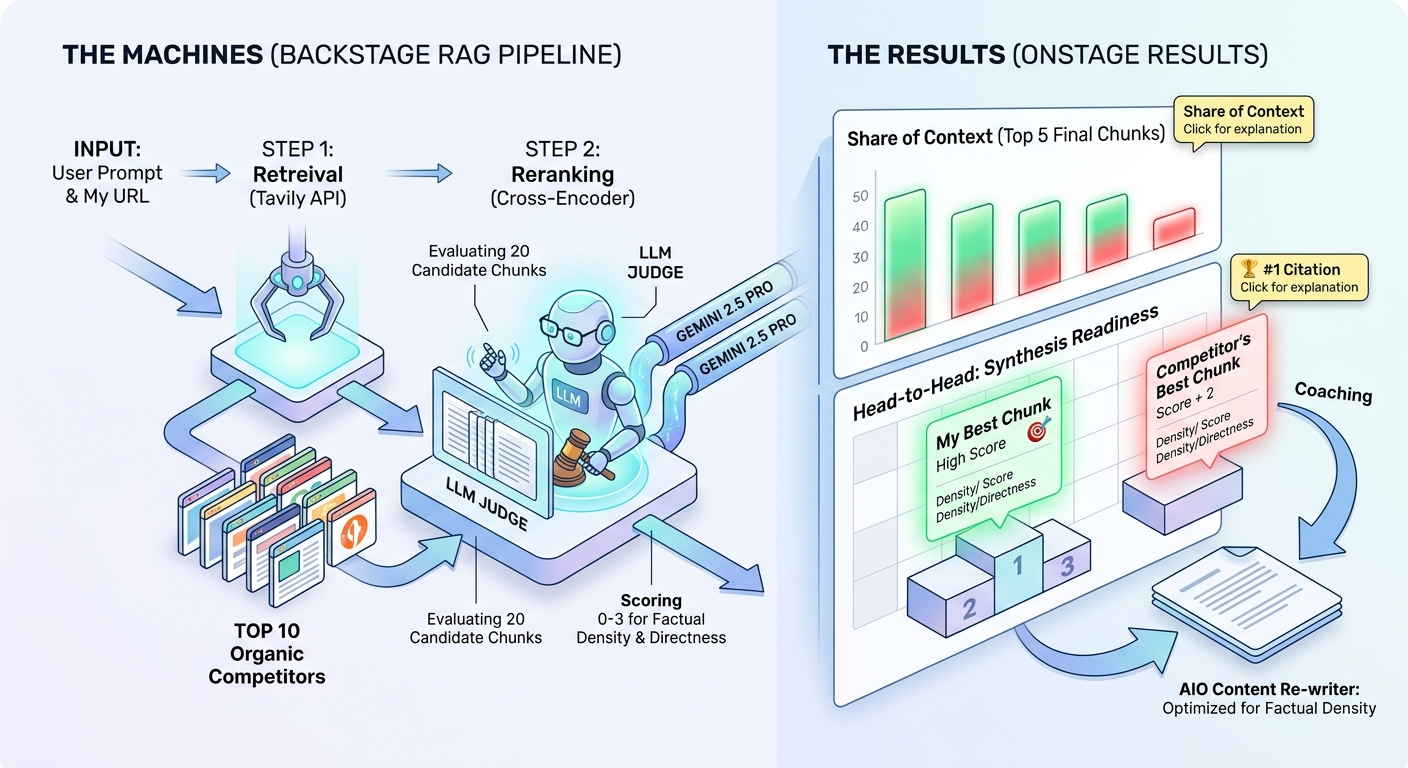
Das System berechnet die geometrische Distanz (Cosine Similarity) zwischen den Dual-HyDE-Vektoren und den verfügbaren Child-Chunk-Vektoren. Dies ist ein rein mathematischer Filter, der die am besten matchenden Fragmente isoliert und via Auto-Merging zurück an ihre Parent-Chunks übergibt. - Algorithmic LLM Re-Ranking (Cross-Encoder Judge)
Semantische Ähnlichkeit (Vektor-Match) garantiert keine inhaltliche Qualität. Ein deterministisches Evaluierungsmodell (LLM-as-a-Judge) liest die Top-20 Chunks und bewertet sie anhand von Factual Density, Directness und Completeness mit einem harten Score von 0 bis 100. Rhetorischer „Marketing-Fluff“ wird hierbei algorithmisch abgestraft. - Calibrated Probability & Context Window Assembly
Das System aggregiert die Top-5 Chunks und errechnet die Calibrated Citation Probability. Anstatt sich auf fehleranfällige LLM-Halluzinationen zu verlassen, nutzt das Tool einen 60/40 Split: Eine Retrieval Prior (Share of Context × Entity Overlap × Intent Alignment) gewichtet mit 60%, kombiniert mit einer generativen Monte-Carlo-Simulation (40%). Das Ergebnis ist ein KPI für die Wahrscheinlichkeit, in der AI-Antwort als Quelle zitiert zu werden. - Section-Aware Synthesis & AIO Re-Write
Das Context Window wird an das finale LLM übergeben. Wir zwingen die „Attention Heads“ des Modells durch eine strikte thematische Architektur (Definition, Mechanism, Edge Cases, Examples) in eine deterministische Rolle (Structured Assembly Engine). Parallel berechnet das System Entity Gaps und Information Gain im Vergleich zu den Wettbewerbern, um einen maßgeschneiderten, hochverdichteten Re-Write für den Nutzer zu generieren. - Visual Rendering & Negative Signal Harvesting
Die analytischen Ergebnisse, Scores und Gaps werden in ein UI gerendert, das präzise Audits ermöglicht. Gleichzeitig erntet ein Hintergrund-Telemetrie-Prozess lautlos „Negative Signals“ (False Positives: Chunks mit hohem Vektor-Match, aber miserablem LLM-Score). Diese Daten sind eine wahre Goldmine für kontinuierliches Prompt-Tuning.
Grenzen des RAG-Simulators: Das Fehlen von Query Fan-Out
Um realistische Erwartungen an die Daten zu setzen, muss eine aktuelle Limitation des RAG-Simulators benannt werden: Das System nutzt aktuell kein Query Fan-Out (Query Decomposition).

Bei hochkomplexen Prompts, zum Beispiel vergleichenden Analysen oder langen Fragestellungen, splitten fortgeschrittene KI Antwort-Systeme die Suchanfrage dynamisch in mehrere Sub-Queries auf, um parallele Retrieval-Prozesse zu starten und ein breiteres Context Window aufzubauen.
Mein Tool verarbeitet die Suchanfrage (nach der HyDE-Generierung) derzeit noch als singulären Vektor. Für granulare Standard-Suchanfragen ist diese Pipeline hochgradig präzise; bei extrem verschachtelten Multi-Intent-Anfragen kann das Retrieval jedoch an seine Grenzen stoßen.
Die Implementierung einer dynamischen Multi-Query-Routing-Ebene, ist für zukünftige Iterationen des Open-Source-Frameworks geplant.
Offen für Diskussion & Ihre eigenen Tests
Dieses SEO-Tool und die daraus resultierenden Daten repräsentieren eine Arbeitshypothese.
Wenn die technische Annahme zutrifft, dass deterministisches Retrieval und faktische Dichte eine wesentlich höhere Gewichtung haben als klassische Brand Authority, liefert der Output dieses Simulators hochgradig anwendbare Optimierungsdirektiven.
Jede Theorie muss sich jedoch letztlich in der Praxis beweisen. Deshalb lade ich Sie ein, den RAG Pipeline Simulator mit Ihren eigenen URLs und echten User-Prompts auf die Probe zu stellen.
Analysieren Sie Ihren „Share of Context“, decken Sie Ihren Entity Gap auf, experimentieren Sie mit den generierten Optimierungsvorschlägen und prüfen Sie, ob sich die algorithmische Gewichtung durch gezielte inhaltliche Verdichtung zu Ihren Gunsten verschiebt.
Teilen Sie Ihre Ergebnisse, Beobachtungen und kritischen Einwände. Nur durch kollektives Testen und den offenen Diskurs können wir diese Hypothese validieren und die Blackbox der modernen KI Antwortsystemen Schritt für Schritt entschlüsseln.
Den Link zum Tool sowie den kompletten Open-Source-Code finden Sie hier in meinem GitHub-Repo.
Über den Autor & Strategische Beratung
René Dhemant ist Principal SEO Strategist mit Spezialisierung auf die Schnittstelle von Information Retrieval und Generativer KI. Er berät Unternehmen und Inhouse-Teams bei der Auditierung und Umstrukturierung komplexer Content-Architekturen.

Anstatt auf klassische SEO-Metriken zu vertrauen, setzt seine Beratung auf deterministische Frameworks: Content wird gezielt auf Vektor-Distanz, Factual Density und Entity-Vollständigkeit optimiert, um das Context Window der RAG-Pipelines mathematisch zu dominieren und als finale Quelle in die Antwortsynthese zu kommen.
Sichern Sie sich Ihren Share of Context und machen Sie Ihre Informationsarchitektur bereit für modernes AI-Retrieval.
FAQ Optimierung für KI Antwort-Systeme
Was ist der Unterschied zwischen dem deterministischen Retrieval und der probabilistischen Generierung in RAG-Systemen?
Der entscheidende Unterschied liegt in der Vorhersehbarkeit. Das deterministische Retrieval ist ein rein mathematischer Prozess, der anhand fester Regeln wie Vektor-Distanz die relevantesten Informations-Chunks auswählt. Diese Phase ist messbar und optimierbar. Die probabilistische Generierung hingegen ist der kreative, aber unberechenbare Teil, bei dem das LLM aus den ausgewählten Chunks eine sprachlich neue Antwort formuliert.
Warum ist intelligentes Text Chunking wie Parent/Child so entscheidend für RAG-Systeme?
Intelligentes Chunking wie die Parent/Child-Methode löst das Problem des „Vector Blur“. Ganze Webseiten sind semantisch zu unscharf. Durch die Aufteilung in kleine, präzise Child-Chunks für den Vektor-Abgleich und größere Parent-Chunks, die den Gesamtkontext bewahren, wird eine hohe mathematische Treffsicherheit im Retrieval-Prozess erreicht, ohne den übergeordneten Sinn zu verlieren.
Wie hilft mir der RAG-Simulator konkret dabei, meine Inhalte für KI-Antworten zu optimieren?
Der RAG-Simulator macht die sonst verborgene, deterministische Auswahlphase von KI-Systemen transparent. Er analysiert Ihre URL im Vergleich zu Wettbewerbern und zeigt genau, welche Text-Chunks mathematisch bevorzugt werden. So können Sie gezielt Ihren „Share of Context“ erhöhen, Informationslücken (Entity Gaps) schließen und Inhalte auf Basis von faktischer Dichte statt auf vagen Keywords optimieren.
Wie bewertet ein Cross-Encoder die Qualität von Inhalten und warum wird ‚Marketing-Fluff‘ abgestraft?
Ein Cross-Encoder agiert als strenger Qualitätsprüfer nach der ersten Vektorsuche. Er vergleicht die vorausgewählten Text-Chunks direkt mit der Nutzeranfrage und bewertet sie nach Kriterien wie faktischer Dichte, Direktheit und Vollständigkeit. Rhetorische Füllwörter und vager „Marketing-Fluff“ erhalten einen niedrigen Score, da sie keine präzisen Informationen liefern und somit algorithmisch abgestraft werden.

