
Die Behauptung, dass Large Language Model (LLM) Chatbots, Retrieval-Augmented Generation (RAG) Pipelines und KI-Crawler (wie GPTBot, ClaudeBot oder OAI-SearchBot) strukturierte Daten im JSON-LD-Format auf genau dieselbe Weise lesen, interpretieren und nutzen wie der Googlebot, ist ein weit verbreiteter Irrglaube in der SEO- und Marketing-Community.
Inhaltsverzeichnis
Während klassische Suchmaschinen JSON-LD deterministisch nutzen, um starre relationale Datenbanken (Knowledge Graphs) zu füttern, sind LLMs und RAG-Architekturen probabilistische Text-Generatoren, die auf Natural Language Processing (NLP) und strikte Token-Limits optimiert sind.

Um zu verstehen, warum KI-Bots keine strukturierten Daten nutzen, muss man sich ansehen, wie KI-Crawler und Data-Ingestion-Pipelines mit Standard-Frameworks wie LangChain und LlamaIndex gebaut werden.
tl;dr
Es ist ein Irrglauben, dass KI-Bots strukturierte Daten im JSON-LD-Format auf die gleiche Weise verarbeiten wie klassische Suchmaschinen. Während der Googlebot diese Daten für seinen Knowledge Graph nutzt, filtern moderne KI-Crawler solche Skripte meist aktiv raus, um die Token-Effizienz zu steigern und Rauschen zu minimieren. In sogenannten RAG-Pipelines wird lediglich der sichtbare Text extrahiert, während technischer Code wie script als hinderlich für die semantische Analyse gilt. Dennoch behält JSON-LD eine indirekte Relevanz, da es die Auffindbarkeit in den traditionellen Such-Indizes verbessern kann, welche KI-Systemen u.a. als primäre Quellen beim Grounding dienen. Letztlich ist das strukturierte Markup für die eigentliche Antwortgenerierung durch das Sprachmodell irrelevant.

🗑️ KI-Parser werfen JSON-LD in den Papierkorb
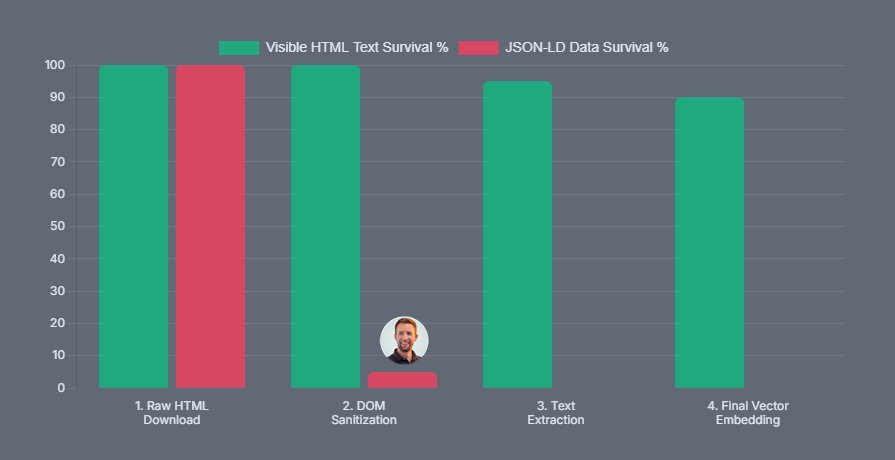
Standard-RAG-Pipelines extrahieren nur den sichtbaren Text in sauberes Markdown. Um Rauschen zu minimieren, werden script-Tags aktiv herausgefiltert. Das gesamte JSON-LD wird restlos gelöscht, bevor die Daten das Context Window des Sprachmodells überhaupt erreichen.
🧠 Grund ist Token-Ökonomie statt Datenbank
LLMs sind probabilistische Text-Generatoren, keine relationalen Datenbanken. Komplexe JSON-Syntax verschwendet teure Tokens und verschlechtert das semantische Verständnis der Vektordatenbanken.
🔍 Selbsternannte Experten verwechseln Retrieval und Synthesis
Warum behaupten dann so viele, man brauche JSON-LD für die „KI-Suche“? Weil sie die Abruf- und Synthese-Ebene verwechseln. Die Verwechslung von Retrieval und Synthesis führt zur falschen Annahme, dass JSON-LD für die KI-Antwortgenerierung notwendig ist. Der Prozess ist zweistufig:
- Retrieval: Chatbots nutzen oft traditionelle Such-APIs, bei denen JSON-LD die Auffindbarkeit einer URL als potenzielle Quelle verbessern kann
- Synthesis: Nachdem eine URL abgerufen wurde, parst der KI-Crawler nur den sichtbaren Text für die Antwortformulierung durch das LLM. In dieser Phase wird der JSON-LD-Code verworfen
Gewinnen Sie handfeste und datenbasierte SEO-Handlungsempfehlungen, anstatt sich auf Ihr Bauchgefühl verlassen zu müssen (oder auf das lediglich angelesene Buchwissen Dritter).
RAG Data Loader filtern script-Tag heraus
RAG Data Loader verwenden HTML-to-Text-Parser, um rohes HTML in sauberen Text umzuwandeln, bevor er an ein LLM übergeben wird. Dieser Schritt ist notwendig, da RAW-HTML und JSON-LD als rauschbehaftet (noisy) gelten und übermäßig viele Tokens im Kontextfenster des Modells beanspruchen. Gängige Parser-Bibliotheken für diese Aufgabe sind Trafilatura, Mozilla’s Readability.js oder Beautiful Soup, die darauf spezialisiert sind, nur den für Menschen lesbaren Inhalt zu extrahieren. Wenn eine KI eine Webseite abruft, übergibt sie dem LLM nicht das rohe HTML.
RAG Data Loader sind spezialisierte Komponenten innerhalb von Retrieval-Augmented Generation (RAG)-Pipelines, die Daten aus unterschiedlichsten Quellen (PDFs, Websites, Datenbanken, Dokumente) einlesen, verarbeiten und in ein für das KI-Modell nutzbares Format umwandeln.
Wie ein HTML-to-Text-Parser arbeitet
Das Hauptziel dieser Extraktions-Bibliotheken (HTML-Parser) ist es, den sichtbaren Hauptinhalt (Main Content) zu isolieren und in sauberes Markdown umzuwandeln. Um dies zu tun, ohne die Vektordatenbank (Vector Database) der KI mit JavaScript-Code zu verschmutzen, filtern Standard-Parser aktiv Boilerplate-Code, Navigationselemente und alle anderen Elemente heraus.
<script>, <style>, <head>Da Schema.org JSON-LD immer über script type=“application/ld+json“ injiziert wird, wird es während des Extraktions- und Chunking-Prozesses vollständig gelöscht. Das JSON-LD landet buchstäblich im Papierkorb, bevor der Text jemals das Kontextfenster (Context Window) des LLMs erreicht.
RAG-Systeme ignorieren strukturierte Metadaten
Echten Experten ist sehr wohl bewusst, dass aktuelle Architekturen von Retrieval-Augmented Generation (RAG)-Systemen strukturierte Metadaten wie JSON-LD nicht nativ verarbeiten können. Eine Studie mit dem Titel „Structured Linked Data as a Memory Layer for Agent-Orchestrated Retrieval“ (arXiv:2603.10700, veröffentlicht im März 2026) untersuchte die Auswirkungen von JSON-LD-Schema auf die Leistung von RAG-Systemen.
Die Forscher stellten explizit fest: „Websites betten zunehmend strukturierte Daten via Schema.org JSON-LD ein, dennoch nutzen RAG-Systeme diese Metadaten kaum. Trotz dieser Fortschritte operieren bestehende RAG-Systeme überwiegend auf unstrukturiertem Text.“

Das Fazit der Studie arXiv:2603.10700
Standardmäßiges Text-Chunking zerstört die hierarchischen Beziehungen von JSON-Arrays.
Um ein LLM tatsächlich dazu zu zwingen, strukturierte Daten wie eine Datenbank zu nutzen, mussten die Forscher den Standard-RAG-Prozess aufgeben und eine maßgeschneiderte „Agentic RAG“-Pipeline bauen, die explizit darauf programmiert war, HTTP-Content-Negotiation durchzuführen, um Links zu traversieren (crawlen). Standardmäßige „Out-of-the-box“ KI-Chatbots und -Crawler tun dies nicht.
Das Experiment von serchVIU
Ein maßgebliches empirisches Experiment, das SearchVIU im Jahr 2025 durchführte, prüfte genau diese These anhand von fünf bedeutenden KI-Systemen: Googles KI-Modus (Overviews), Perplexity, ChatGPT, Claude und Gemini. Die Methodik war darauf ausgelegt, die Analyse strukturierter Daten isoliert zu betrachten. Michael Weber platzierte bestimmte Produktpreise ausschließlich innerhalb des JSON-LD-Schema-Markups. Das Ergebnis des Experiments: Keine Extraktion des versteckten Schemas. Keines der fünf getesteten KI-Systeme hat das JSON-LD-Schema-Markup während des direkten Live-Abrufs extrahiert oder verwendet.
Token-Ökonomie vs. Deterministisches Parsing
Viele gehen davon aus, dass KI-Bots JSON-LD benötigen, weil sie annehmen, dass KI-Bots Daten genau wie der Googlebot verarbeiten. Dies ist ein grundlegendes Missverständnis informatischer Paradigmen.
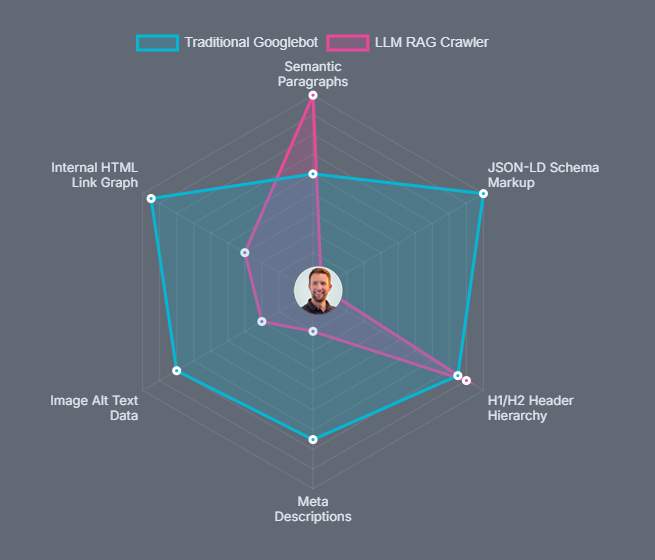
Wie der Googlebot funktioniert (Deterministisch)
Der Googlebot arbeitet deterministisch und nutzt einen dedizierten, regelbasierten Parser zur Verarbeitung strukturierter Daten wie JSON-LD. Dieser Ansatz ermöglicht es ihm, Datenfelder exakt zu identifizieren, zu validieren und die extrahierten Entitäten und ihre Beziehungen in seinem Wissensgraphen (Knowledge Graph) zu speichern.
Wenn Googlebot
{"@type": "Recipe", "cookTime": "PT1H"}sieht, ordnet er die exakte Syntax direkt seiner Knowledge-Graph-Datenbank zu. Er „liest“ die Daten nicht im semantischen Sinne; er legt sie ab (Indexing).
Wie LLMs funktionieren (Probabilistischer Text)
LLMs besitzen ein semantisches Verständnis, was bedeutet, dass sie sich auf implizite Struktur (Markdown, H1/H2-Überschriftenhierarchie, Aufzählungen und HTML-Tabellen) verlassen. Falls ein KI-Bot doch versehentlich ein tief verschachteltes JSON-LD-Skript aufnimmt, liest er es als eine flache Sequenz von Text-Tokens.
Ein LLM mit stark verschachteltem JSON-LD zu füttern, führt zu „Token Bloat“. der Verschwendung wertvoller Token für Syntaxklammern { , „@type“, [ , ] anstelle von echter semantischer Bedeutung.
Dies verschlechtert die semantische Ähnlichkeitssuche (Semantic Similarity Search), die von Vektordatenbanken verwendet wird.
Die DHEMANT Consulting GmbH bietet professionelle SEO-Beratungsdienste, um die Online-Sichtbarkeit von Unternehmen und die Platzierung in der organischen Google-Suche zu verbessern. Das oberste Ziel ist die Steigerung der Wirtschaftlichkeit Ihres Internetangebots.
Warum hält sich dieser Irrglaube hartnäckig?
Wenn JSON-LD für das LLM selbst keine Rolle spielt, warum behaupten dann so viele ständig, man bräuchte es für die „AI Search Optimization“?
Diese Leute verwechseln den Retrieval Layer (Abrufebene) mit dem Synthesis Layer (Syntheseebene).
Wenn Chatbots wie ChatGPT Search, Microsoft Copilot oder Perplexity nach Antworten suchen, crawlen sie das gesamte Web nicht blind. Die KI-Bots fragen einen klassischen Suchindex (wie die Bing Search API oder den Google-Index) ab, um URLs zu finden (Retrieval). Da klassische Suchmaschinen wie Google JSON-LD sehr wohl für das Ranking nutzen, kann ein vorhandenes Schema auf Ihrer Seite dabei helfen, von der zugrundeliegenden Search API überhaupt erst als Quelle an die KI empfohlen zu werden.
Sobald die Search API Ihre URL jedoch an den KI-Crawler übergibt, reduziert der Crawler die Seite auf den rohen sichtbaren Text, wirft das JSON-LD weg, und das LLM liest das resultierende Markdown, um die finale Antwort zu generieren (Synthesis).
Marketer sehen dann, dass die KI ihre Seite zitiert, und ziehen den falschen Schluss, dass das LLM das Schema gelesen hat. In Wahrheit hat das LLM lediglich den sichtbaren Text einer Seite gelesen, die zuvor von der klassischen Suchmaschine empfohlen wurde.
Prävention dank SEO-Seminar 😌
René Dhemant legt großen Wert auf fundiertes SEO-Wissen in Unternehmen oder Agenturen und lehnt schnelle Tipps ohne Kontext entschieden ab.
Seine Hilfe als strategischer SEO-Berater zielt darauf ab, teure Beschäftigungstherapie in ein profitables Asset zu verwandeln.
Die maßgeschneiderten SEO-Seminar und inhouse Schulungen werden genau dafür häufig gebucht.

FAQ LLM & JSON-LD
Warum ignorieren KI-Chatbots wie ChatGPT meine strukturierten JSON-LD-Daten?
Standard-RAG-Pipelines, die von KI-Crawlern genutzt werden, filtern aktiv alle script-Tags heraus, um Rauschen zu minimieren. Da JSON-LD in diesen Tags platziert wird, wird es komplett gelöscht, bevor der Text das Sprachmodell erreicht. Der Grund ist Token-Ökonomie: Komplexe JSON-Syntax verschwendet teure Tokens.
Was ist der Unterschied, wie Googlebot und ein KI-Crawler meine Webseite lesen?
Der Googlebot ist deterministisch und nutzt JSON-LD, um Daten exakt in seinen Knowledge Graph einzuspeisen. KI-Crawler hingegen sind probabilistisch und für Textverständnis optimiert. Sie verwerfen JSON-LD und extrahieren nur den sichtbaren Text, um ihn semantisch zu analysieren und Antworten zu generieren.
Warum ist JSON-LD trotzdem wichtig, auch wenn KI-Bots es für die Antwortgenerierung ignorieren?
Der Prozess ist zweistufig. In der ersten Phase (Retrieval) nutzen KI-Chatbots oft klassische Such-APIs wie Google oder Bing. Da diese JSON-LD für das Ranking nutzen, hilft es Ihrer Seite, überhaupt als relevante Quelle für die KI ausgewählt zu werden, auch wenn die KI es in der Synthese-Phase später verwirft.
Wie verarbeiten RAG-Systeme den Inhalt einer Webseite, bevor ein LLM ihn liest?
RAG-Pipelines nutzen HTML-to-Text-Parser, um nur den sichtbaren Hauptinhalt zu extrahieren. Dabei werden Navigation, Boilerplate-Code und alle script-Tags – inklusive JSON-LD – entfernt. Das rohe HTML wird in sauberes Markdown umgewandelt, um die Token-Nutzung für das Sprachmodell zu optimieren.
Was bedeutet der Begriff Token-Ökonomie im Zusammenhang mit LLMs und JSON-LD?
Token-Ökonomie beschreibt das Prinzip, das begrenzte Context Window eines LLMs effizient zu nutzen. Komplexe JSON-LD-Syntax mit vielen Klammern und Anführungszeichen verbraucht wertvolle Tokens, ohne semantischen Mehrwert zu liefern. Reiner, sichtbarer Text ist für das probabilistische Modell deutlich effizienter.

