Überprüfen Sie sofort, ob Ihre Website das Abrufen durch KI-Scraper verhindert. Wenn Ihnen Markensichtbarkeit und Zitierungen in LLM-ChatBots wichtig ist, müssen die KI-Bots Ihre Seite & Inhalte verarbeiten dürfen.
Website AI Bot 🤖 Checker (Tool)
Analysieren Sie Ihre Domain, um zu sehen, welche KI-Bots blockiert oder zugelassen sind. Funktioniert auch mit Ihrer Konkurrenz 💡
Max. 15 Abfragen pro Person und Tag. CMS-Erkennung ist Beta-Funktion.
| Bot User-Agent | Status | Reason |
|---|
Genauso wie Sie Ihre Webseite für Google optimieren, müssen Sie nun sicherstellen, dass KI-Chatbots wie ChatGPT, Claude und Gemini Ihre Inhalte tatsächlich abrufen können. Dieser kostenlose KI-Bot Checker scannt die technischen Berechtigungen Ihrer Website (die robots.txt-Datei) und teilt Ihnen sofort mit, ob Sie genau die KI-Modelle blockieren, die potenzielle Kunden zur Suche nach Antworten verwenden.

Dieses kostenlose SEO-Tool scannt die robots.txt-Datei Ihrer Domain, um zu überprüfen, welche KI-Bots & Crawler (ChatGPT, Claude, CCBot etc.) auf Ihre Inhalte zugreifen dürfen oder blockiert werden.
Funktionsumfang SEO-Tool AI Bot Checker v8.69
Plattform
Benutzerdefiniertes WordPress-Plugin/Snippet (PHP & jQuery) mit Proxy-Server.
Kernfunktion
Überprüft die Zugriffsberechtigungen für bestimmte Bot-User-Agents durch parsen und validieren der robots.txt-Datei der untersuchten Domain.
Datenabruf
Ruft Live-robots.txt-Dateien über einen Proxy-Dienst ab, um Host-Firewalls und IP-Blocks zu umgehen.
Parsing-Logik
Serverseitiges Parsing der robots.txt-Syntax, Verarbeitung spezifischer User-Agent-Direktiven, Platzhalter (*) und Disallow-Regeln.
Bot-Datenbank
Überprüft anhand einer kuratierten Bibliothek mit über 100 User-Agents, die in KI/LLMs, Suchmaschinen und kommerzielle Scraper kategorisiert sind.
Antwortverarbeitung
Gibt einen JSON-Statusbericht zurück, der angibt, ob ein Bot ausdrücklich zugelassen, ausdrücklich abgelehnt oder über einen Platzhalter blockiert ist.
Website AI Bot 🤖 Checker Tool-Beschreibung für SEO
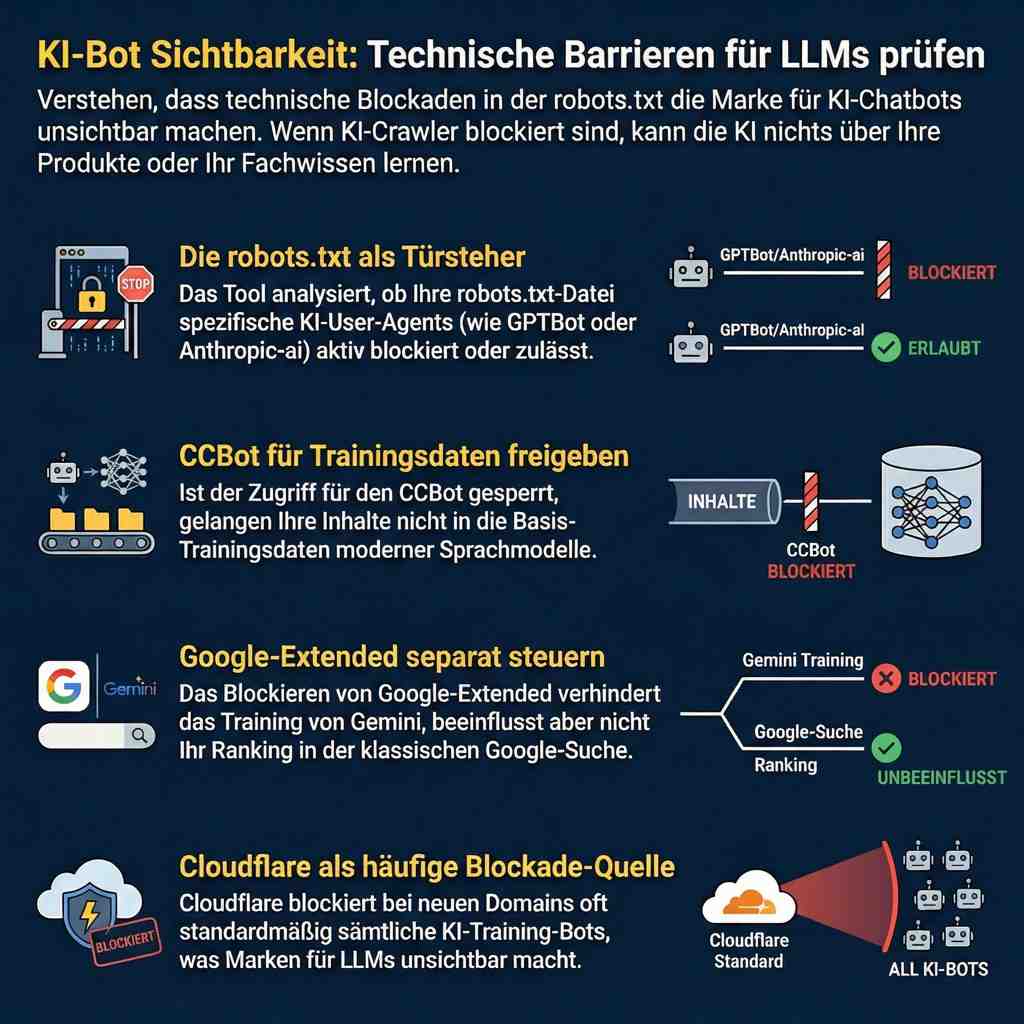
Dieses Tool ist Ihr erster Schritt, um in der neuen Ära der KI-Suche sichtbar zu werden. Genauso wie Sie Ihre Website für Google optimieren, müssen Sie nun sicherstellen, dass KI-Chatbots wie ChatGPT, Claude und Gemini Ihre Inhalte tatsächlich abrufen können. Dieser kostenlose KI-Bot Checker scannt die technischen Berechtigungen Ihrer Website (die robots.txt-Datei) und teilt Ihnen sofort mit, ob Sie genau die KI-Modelle blockieren, die potenzielle Kunden zur Suche nach Antworten verwenden. Wenn diese Bots blockiert sind, ist Ihre Marke für sie unsichtbar, was bedeutet, dass Sie in ihren generativen Antworten nicht zitiert, erwähnt oder empfohlen werden. Wenn ein KI-Modell auf Ihre Website nicht zugreifen kann, wird es nichts über Ihre Produkte, Dienstleistungen oder Ihr Fachwissen lernen. Mit diesem kostenlosen SEO-Tool können Sie überprüfen, welche KI-Crawler Zugriff auf Ihre Daten haben und welche blockiert werden. Möglicherweise auch unbeabsichtigt durch eine Einstellung bei Cloudflare. Dieses SEO-Tool erkennt auch, ob Ihre Website durch Cloudflare geschützt ist oder auf bestimmten Plattformen wie Shopify oder WordPress läuft. Dieser kostenlose KI-Bot Checker wurde speziell für Anfänger entwickelt und erfordert keine Programmierkenntnisse. Geben Sie einfach Ihre Domain ein und innerhalb von Sekunden erhalten Sie einen eindeutigen Status Zulässig oder Blockiert für jeden wichtigen KI-Bot. Damit haben Sie die Kontrolle über Ihre digitale Präsenz und stellen sicher, dass Sie sich nicht versehentlich vor der Zukunft der Suche verstecken. Ganz gleich, ob Sie Ihre Inhalte vor Scrapern schützen oder sich für AI-generierte Antworten öffnen möchten, dieses kostenlose Tool bietet Ihnen die Transparenz, die Sie für diese Entscheidung benötigen.
SEO-Tool KI-Bot 🤖 Validator
Inhaltsverzeichnis
Dieses SEO-Tool prüft die Zugriffsberechtigungen von KI-Bots & Crawlern. Das Dienstprogramm akzeptiert eine vom Benutzer eingegebene Root-Domain, ruft die Live-Datei robots.txt über einen Proxy-Dienst ab und analysiert die Regeln serverseitig.
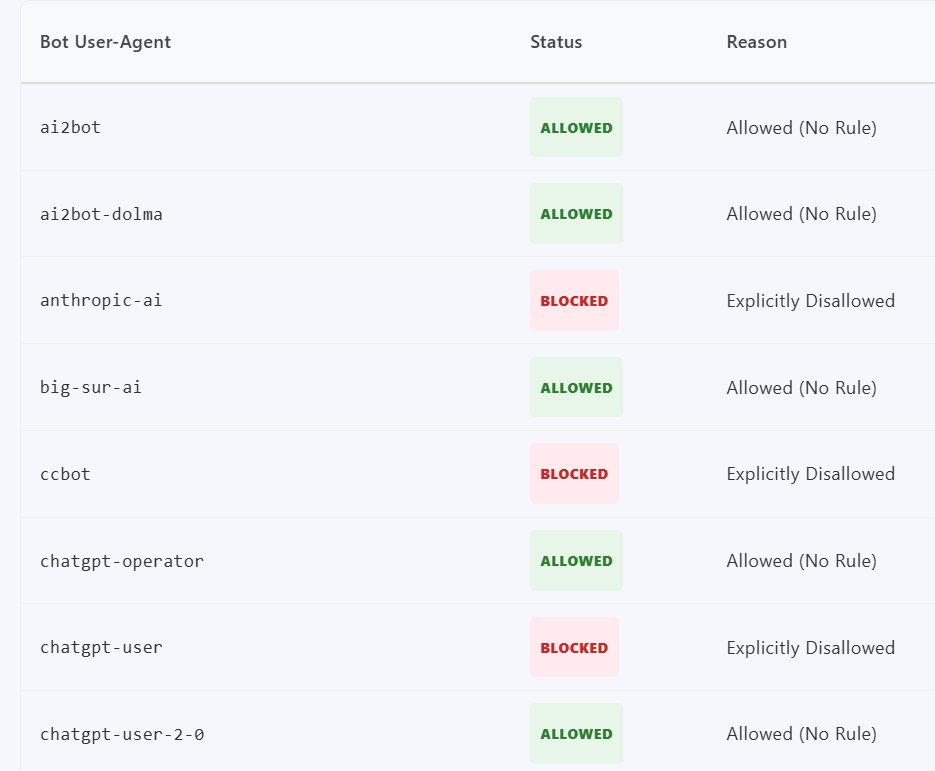
Anschließend gleicht das Tool die analysierten Regeln mit einer kuratierten Datenbank bekannter User-Agents ab. Diese sind kategorisiert in AI LLMs, Suchmaschinen, CCBot Common Crawl und kommerzielle Scraper.
User-Agent CCBot blockiert
SEO-Tipp: Prüfen Sie unbedingt den CCBot. Ist sein Zugriff gesperrt, gelangen Ihre Inhalte nicht in die Trainingsdaten moderner KI-Modelle (ChatGPT, Claude etc.)
Das kostenlose SEO-Tool gibt einen einen JSON-Statusbericht zurück, der angibt, ob jeder einzelne Bot ausdrücklich (/allow) zugelassen, ausdrücklich abgelehnt (/disallow) oder über einen Platzhalter (*/) blockiert ist.
User-Agent Google-Extended blockiert
SEO-Tipp: Der User-Agent Google-Extended entscheidet darüber, ob Ihre Inhalte zum trainieren der generativen API Gemini und Vertex AI herangezogen werden dürfen.

Das Blockieren von Google-Extended hat keine Auswirkungen auf die Sichtbarkeit, Indizierung oder das Ranking einer Website in der Google-Suche.
User-Agent ChatGPT-User blockiert
SEO-Tipp: Der User-Agent ChatGPT-User wird von OpenAI verwendet, wenn ein Benutzer ChatGPT ausdrücklich auffordert, im Internet nach einer Antwort in Echtzeit zu suchen.
Übersicht aller Bots 🤖 mit Beschreibung
Tabelle öffnen 👀
🤖 1. AI & LLM Crawlers
These bots are primarily used to scrape data to train Artificial Intelligence models, or they act as live-search agents for AI chatbots fetching real-time answers for users.
| Bot User-Agent | Description |
|---|---|
| ai2bot / ai2bot-dolma | Crawlers for the Allen Institute for AI (AI2), used to build open-source datasets like Dolma. |
| anthropic-ai | General crawler for Anthropic, the company behind the Claude AI models. |
| big-sur-ai | Crawler associated with Big Sur AI, an AI-powered e-commerce platform. |
| chatgpt-operator | OpenAI’s bot used for autonomous actions and system-level ChatGPT tasks. |
| chatgpt-user / chatgpt-user-2-0 | Used by OpenAI when a user explicitly asks ChatGPT to browse the web for a real-time answer. |
| claude-code | Anthropic’s bot associated with coding assistants and code-related queries. |
| claude-searchbot / claude-web | Used by Claude when it performs real-time web searches to answer user prompts. |
| claude-user / claudebot | General crawlers used by Anthropic to index web data for Claude’s knowledge base. |
| cohere-ai | Crawler for Cohere, an enterprise-focused AI and natural language processing platform. |
| cohere-training-data-crawler | Explicitly used by Cohere to scrape web data for training their LLMs. |
| deepseekbot | Crawler for DeepSeek, a prominent AI research company and LLM developer. |
| digitaloceangenai-crawler | Used by DigitalOcean for their generative AI infrastructure and cloud tools. |
| duckassistbot | DuckDuckGo’s crawler used specifically to generate AI-assisted search summaries. |
| gemini-deep-research | Google’s advanced crawler for Gemini’s deep research and synthesis capabilities. |
| google-cloudvertexbot | Crawler for Google Cloud’s Vertex AI platform, used for enterprise machine learning. |
| google-extended | The specific user-agent you block if you want to stop Google from using your site to train Gemini. |
| googleother (plus -image, -video) | Generic Google bots often used for internal R&D and AI training rather than search indexing. |
| gptbot | OpenAI’s primary web crawler used to scrape data to train GPT-4 and future models. |
| grok / grokbot | Crawlers for xAI, used to train and power the Grok AI chatbot on X (Twitter). |
| img2dataset | A tool/bot used specifically to scrape images and alt-text to build massive AI image datasets. |
| liner-bot | Crawler for Liner, an AI search engine and research workspace. |
| mistralai-user / -1-0 | Crawlers for Mistral AI, a leading European open-weights AI company. |
| mycentralaiscraperbot | Associated with Central AI, used for data aggregation. |
| oai-searchbot | OpenAI’s crawler used exclusively for SearchGPT and search-related indexing. |
| pangubot | Crawler for Huawei’s PanGu, a massive Chinese AI model. |
| perplexitybot | Perplexity AI’s background crawler used to build their internal index. |
| perplexity-user / -1-0 | Used by Perplexity AI when fetching live web pages to answer a user’s direct query. |
| quillbot-com | Crawler for QuillBot, a popular AI paraphrasing and writing tool. |
| sbintuitionsbot | Crawler for SB Intuitions, an AI research company developing indigenous Japanese LLMs. |
| youbot | Crawler for You.com, an AI-powered search engine and chat platform. |
🔍 2. Search Engines
These are the traditional search engines. Most websites want these bots to crawl their site so they can appear in search results (Google, Bing, etc.).
| Bot User-Agent | Description |
|---|---|
| amzn-searchbot | Amazon’s search bot, often used to index content for Alexa and Amazon search features. |
| applebot / applebot-extended | Apple’s crawler, used for Siri, Spotlight Suggestions, and Apple Intelligence. |
| aspiegelbot | Crawler for Petal Search, Huawei’s primary search engine. |
| baidu / baiduspider | The primary web crawlers for Baidu, the largest search engine in China. |
| bingbot | Microsoft’s primary crawler for Bing search (and by extension, Yahoo and DuckDuckGo). |
| coccocbot-web | Crawler for Cốc Cốc, a highly popular search engine and browser in Vietnam. |
| duckduckbot | DuckDuckGo’s proprietary crawler used to improve their search index. |
| googlebot (plus -image, -news, -video) | Google’s primary web crawlers responsible for indexing the web for Google Search. |
| googlebot-discovery / storebot-google | Specialized Google bots for Google Discover feeds and shopping/store validation. |
| mojeek / mojeekbot | Crawlers for Mojeek, an independent, privacy-focused UK search engine. |
| seekportbot | Crawler for Seekport, a European B2B search engine. |
| seekr / seekrbot | Crawlers for Seekr, an AI-driven search engine focused on content scoring and reliability. |
| seznambot / seznamhomepagecrawler | Crawlers for Seznam, the dominant local search engine in the Czech Republic. |
| slurp / yahoo-* | Yahoo’s web crawlers (often used alongside Bingbot for Yahoo Search properties). |
| teoma | The web crawler for Ask.com (formerly Ask Jeeves). |
| yandex / yandexbot | The primary web crawlers for Yandex, the largest search engine in Russia. |
🛒 3. Commercial & Scrapers
This category includes SEO tools, marketing analyzers, academic scrapers, dataset builders, and general automated scripts. They consume server bandwidth but usually don’t bring direct human traffic.
| Bot User-Agent | Description |
|---|---|
| aliyunsecbot | Alibaba Cloud’s security bot, scanning for vulnerabilities and malicious content. |
| amazonbot / amazon-kendra | Amazon’s general web crawler and its enterprise search service crawler. |
| arquivo-web-crawler | Crawler for Arquivo.pt, a Portuguese web archiving initiative. |
| barkrowler | An open-source web crawler often used by researchers and data scientists. |
| blexbot | A crawler operated by SEO tool WebMeUp to analyze backlinks and site structures. |
| bravest | Background crawler associated with the Brave browser’s search index. |
| bytespider | The massive web crawler operated by ByteDance (the parent company of TikTok). |
| ccbot | Crawler for Common Crawl, an open repository of web crawl data used by researchers and AI companies. |
| cotoyogi | A commercial web scraper often seen aggregating e-commerce and generic web data. |
| crawl4ai / firecrawl | Commercial, developer-focused API tools designed to turn websites into clean data for AI apps. |
| crawler4j / scrapy | Generic, open-source web crawling frameworks used by developers to build custom scrapers. |
| crawlspace | Associated with broad web data extraction and archiving. |
| diffbot | A powerful commercial crawler that uses visual AI to extract structured data (like articles or products) from pages. |
| echobot-bot / echoboxbot | Associated with Echobox, an AI social media publishing tool for publishers. |
| factset-spyderbot | Crawler for FactSet, a financial data and software company gathering market intelligence. |
| friendlycrawler | A generic crawler often used for site performance or uptime monitoring. |
| google-inspectiontool | Used when a site owner manually uses the URL Inspection Tool in Google Search Console. |
| hada-news / news-please | Academic and commercial scrapers specifically targeting news articles and journalism. |
| iaskspider / -2-0 | Crawler for iAsk.AI, an AI-driven search engine and answer engine. |
| icc-crawler / isscyberriskcrawler | Security and risk assessment bots scanning domains for vulnerabilities. |
| imagesiftbot | A crawler focused on extracting images and metadata for databases. |
| jenkersbot | A known aggressive scraper often blocked for ignoring standard crawl delays. |
| kangaroo-bot | A commercial scraper used for market research and data aggregation. |
| livelapbot / mauibot / moodlebot | Various niche scrapers used for academic indexing, analytics, or platform-specific data gathering. |
| magpie-crawler / newsnow | Brand monitoring and news aggregation crawlers. |
| netestate-imprint-crawler | A German bot that crawls websites specifically to find and analyze „Imprint“ (Impressum) pages. |
| novaact | A commercial web crawler used for enterprise data intelligence. |
| omgili / omgilibot | Crawlers for Webhose.io (now Webz.io), gathering data from forums, blogs, and news for sentiment analysis. |
| poseidon-research-crawler | An academic/research crawler gathering data for large-scale web studies. |
| qualifiedbot | Crawler for Qualified, a conversational marketing and chatbot platform for B2B. |
| taragroup-intelligent-bot | A commercial scraper used for business intelligence and data mining. |
| timpibot | Crawler for Timpi, a decentralized, blockchain-based search engine. |
| turnitin | The crawler for Turnitin, the global academic plagiarism detection software. |
| velenpublicwebcrawler | A generic public data aggregation bot. |
| webzio-extended | Enterprise data feed crawler (Webz.io) extracting structured web data for clients. |
| yacy / yacybot | Crawlers for YaCy, a decentralized, peer-to-peer, open-source search engine. |
KI-Sichtbarkeit aktiv steuern ✅

Wenn KI-Bots durch Ihre IT oder Cloudflare blockiert sind, ist Ihre Marke für generative KI-Systeme unsichtbar, was bedeutet, dass Sie in den generativen Antworten der LLM-Chatbots nicht zitiert, erwähnt oder empfohlen werden.
Darf ein KI-Modell nicht auf Ihre Website zugreifen, darf der ChatBot nichts über Ihre Produkte, Dienstleistungen oder Ihr Fachwissen lernen.
Dieses kostenlose SEO-Tool prüft für Sie, welche KI-Crawler Zugriff auf Ihre Daten haben und welche blockiert werden.

Cloudflare blockiert KI-Training-Bots
Möglicherweise auch unbeabsichtigt durch eine Einstellung bei Cloudflare. Der Bot-Checker erkennt auch, ob Ihre Website durch Cloudflare geschützt ist oder auf bestimmten Plattformen wie Shopify oder WordPress läuft.
Verknüpfen Sie eine Domain zum ersten Mal, blockiert Cloudflare standardmäßig sämtliche KI-Training-Bots.
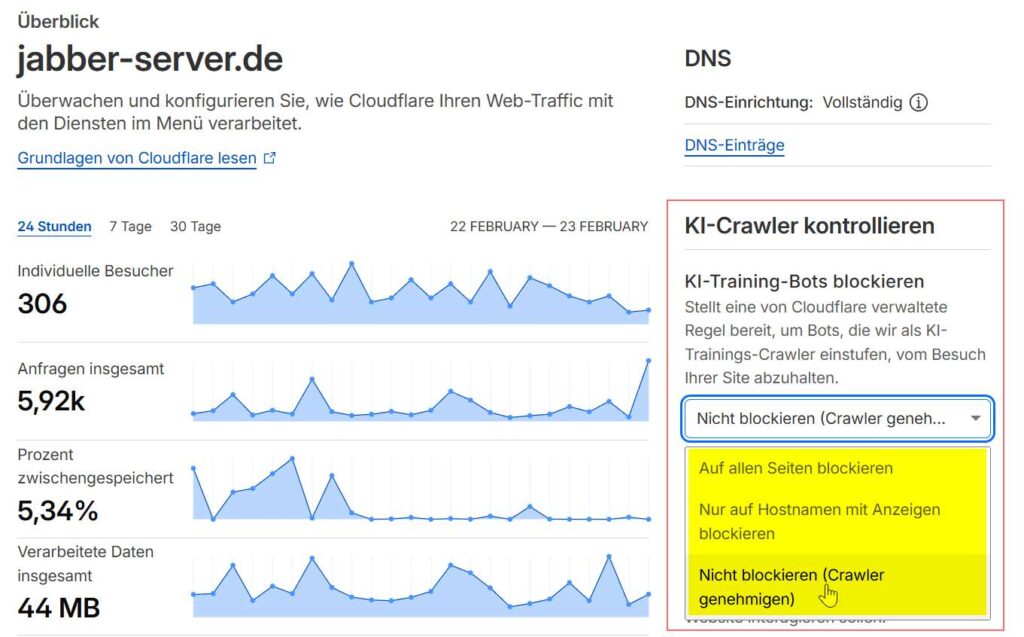
Ganz gleich, ob Sie Ihre Inhalte vor Scrapern schützen oder sich für KI-generierte Antworten öffnen möchten, dieses kostenlose Tool bietet Ihnen die Transparenz, die Sie für Ihre unternehmerischen Entscheidung benötigen.
Gewinnen Sie handfeste und datenbasierte SEO-Handlungsempfehlungen, anstatt sich auf Ihr Bauchgefühl verlassen zu müssen (oder auf das lediglich angelesene Buchwissen Dritter).
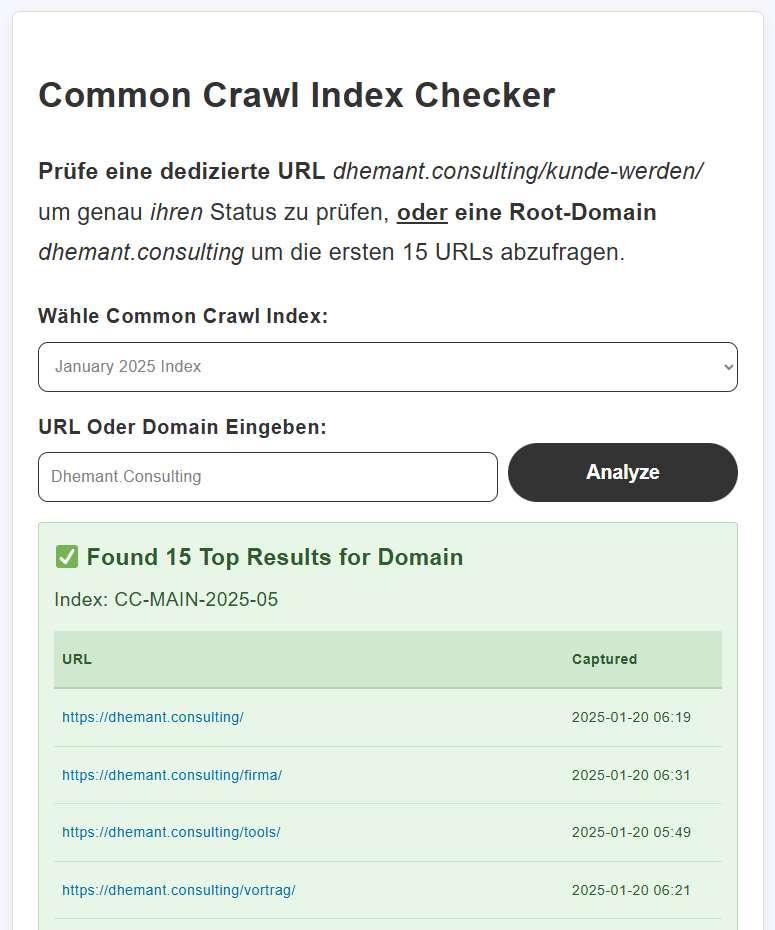
Sind Sie in den Trainingsdaten präsent?
Mit dem ebenfalls kostenlosen Tool Common Crawl Index Checker können Sie anschließend prüfen, ob Inhalte Ihrer Domain bereits im CC-Webindex erfasst wurden und möglicherweise in die Trainingsdaten der großen Sprachmodelle (LLM) eingeflossen sind.