


Tool zur Live-Abfrage, ob Ihre Website im offenen Webarchiv von Common Crawl (CDX-API) enthalten ist. Geben Sie eine spezifische URL ein, um das letzte Erfassungsdatum zu überprüfen, oder geben Sie einen Domainnamen ein, um 15 Seiten anzuzeigen, die vom Crawler (CCBot) indexiert wurden.
Common Crawl Index Checker
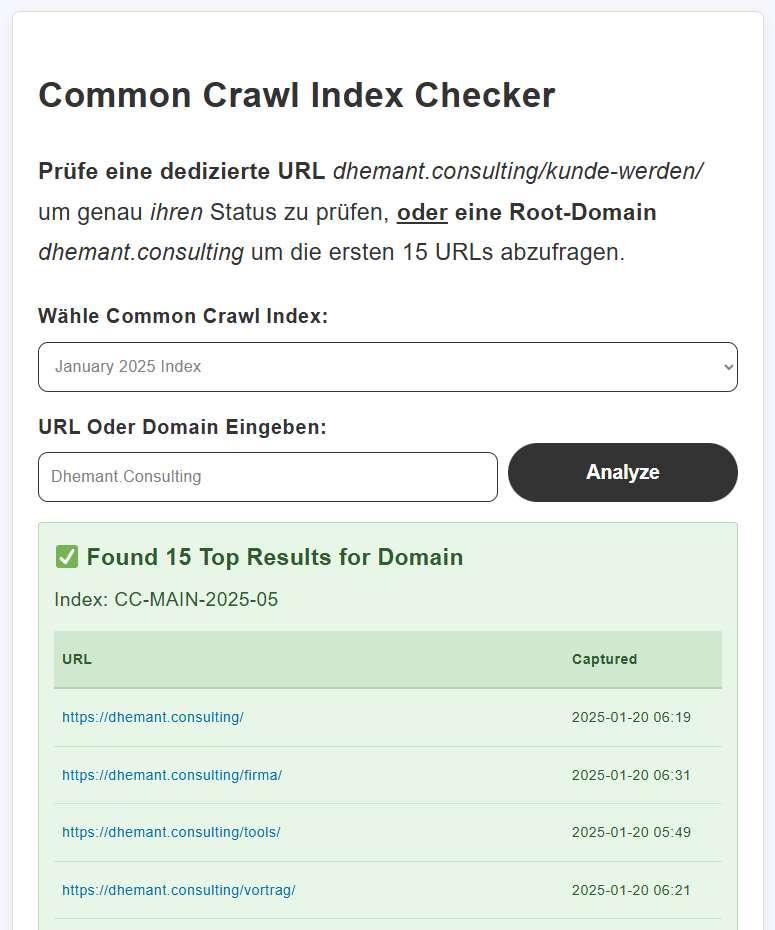
Prüfe eine dedizierte URL dhemant.consulting/kunde-werden/ um genau ihren Status zu prüfen, oder eine Root-Domain dhemant.consulting um die ersten 15 URLs abzufragen.
Funktionen SEO-Tool Common Crawl Index Checker v8.3
AJAX-gesteuerte Architektur
Verwendet standardmäßige WP-AJAX-Endpunkte, um Daten asynchron abzurufen, wodurch ein Neuladen der Seite und Layoutverschiebungen vermieden werden.
Intelligente Abfrageweiterleitung
Unterscheidet automatisch zwischen verschiedenen Eingabetypen: Absolute URLs löst eine exakte Suche (limit=1) zur Statusüberprüfung aus. Root-Domain löst eine Wildcard-Suche (/*.) aus, um indizierte Seiten zu finden.
Heuristische Priorisierung
Nachbearbeitung der Domain-Ergebnisse durch Deduplizierung der Einträge und Sortierung nach URL-Zeichenfolgenlänge, um die Top-15 Seiten (Homepage, Über uns, Kontakt usw.) zurückzugeben.
Ausfallsichere Konnektivität
Leitet Anfragen über einen Proxy weiter, um CORS-Fehler, 403-Blocks und Firewall-Einschränkungen auf Host-Ebene zu umgehen.
Dynamische Indexverwaltung
Ruft automatisch die Live-Liste der Common Crawl-Indizes aus collinfo.json ab und speichert sie über WordPress Transients für 24 Stunden im Cache.
Sicherheit
Implementiert WordPress Nonces für Sicherheit und bereinigt alle Ein- und Ausgänge, um XSS zu verhindern.
Tool-Beschreibung für SEO
Verschaffen Sie sich mit dem Common Crawl Index Checker einen sofortigen Überblick darüber, wie das offene Web Ihre Website sieht. Mit diesem kostenlosen SEO-Tool, entwickelt und bereitgestellt von der DHEMANT Consulting GmbH, können Sie überprüfen, ob Ihre wichtigsten Seiten von dem riesigen Datensatz indexiert werden, der KI-Modelle wie ChatGPT und wichtige Backlink-Recherchetools antreibt. Geben Sie einfach eine bestimmte URL ein, um den letzten Erfassungszeitstempel zu bestätigen, oder geben Sie eine Domain ein, um die 15 Seiten im Archiv anzuzeigen. So können Sie Ihren digitalen Fußabdruck überprüfen und sicherstellen, dass Ihre Inhalte möglicherweise in die Trainsingsdaten der Large Langue Models (LLMs) eingeflossen sind.
SEO-Tool zum abfragen der Common Crawl CDX-API
Dieses kostenlose SEO-Tool zur Abfrage der Common Crawl CDX-API dient der Überprüfung des Indexierungsstatus einer URL in den Common Crawl-Daten. Das Werkzeug sendet Anfragen an die Programmierschnittstelle (API), um zu ermitteln, ob und wann eine spezifische URL vom Common Crawl erfasst wurde, und gibt die entsprechenden Indexeinträge zurück.
Inhaltsverzeichnis
Absolute URLs lösen eine exakte Suche (limit=1) aus, während Domain-Root-Abfragen eine Wildcard-Suche auslösen, die Duplikate entfernt, nach URL-Länge sortiert und ersten 15 Ergebnisse zurückgibt.
Alle API-Anfragen werden über einen Proxy geleitet, um CORS und IP-Blocks auf Host-Ebene zu umgehen.

Common Crawl ist Trainingsdaten vieler LLM (ChatGPT, Claude etc.)
Der Datensatz von Common Crawl ist eine primäre Quelle für Trainingsdaten vieler großer Sprachmodelle (LLMs), einschließlich der Modelle von OpenAI (ChatGPT) und Anthropic (Claude). Die gemeinnützige Stiftung Common Crawl stellt ein frei zugängliches Archiv des World Wide Web bereit, das Ende 2024 über 9 Petabytes an Daten von 275 Milliarden Webseiten umfasste. Diese umfangreiche Text- und Datensammlung ermöglicht es KI-Entwicklern, ihre Modelle auf einem breiten Querschnitt von menschlich erzeugten Informationen zu trainieren..
Während webbasierte Daten in der frühen Phase der Large Language Models (LLMs) aufgrund von Rauschen kritisch betrachtet wurden, bilden sie heute mit einem Anteil von bis zu 80 % das Fundament für das Pre-training moderner Sprachmodelle.
Common Crawl zeichnet sich durch einen verantwortungsbewussten Crawling-Ansatz aus, der CCBot respektiert geltende Standards (robots.txt) und es wird aktiv an neuen Protokollen für die Signalisierung von KI-Präferenzen arbeitet.
Gewinnen Sie handfeste und datenbasierte SEO-Handlungsempfehlungen, anstatt sich auf Ihr Bauchgefühl verlassen zu müssen (oder auf das lediglich angelesene Buchwissen Dritter).
Dürfen KI Bots auf Ihre Website zugreifen?
Ob KI-Bots auf eine Website zugreifen dürfen, wird durch Anweisungen in der robots.txt-Datei im Stammverzeichnis der Domain gesteuert. Website-Betreiber können den Zugriff für spezifische Bots (User-Agents) gezielt erlauben oder verbieten. Mit dem ebenfalls kostenlosen Tool KI Bot 🤖 Checker können Sie nun prüfen, ob Ihre Website das Abrufen durch KI-Scraper (unwissentlich) verhindert.

Darf ein KI-Modell nicht auf Ihre Website zugreifen, kann der ChatBot nichts über Ihre Produkte, Dienstleistungen oder Ihr Fachwissen lernen.

