
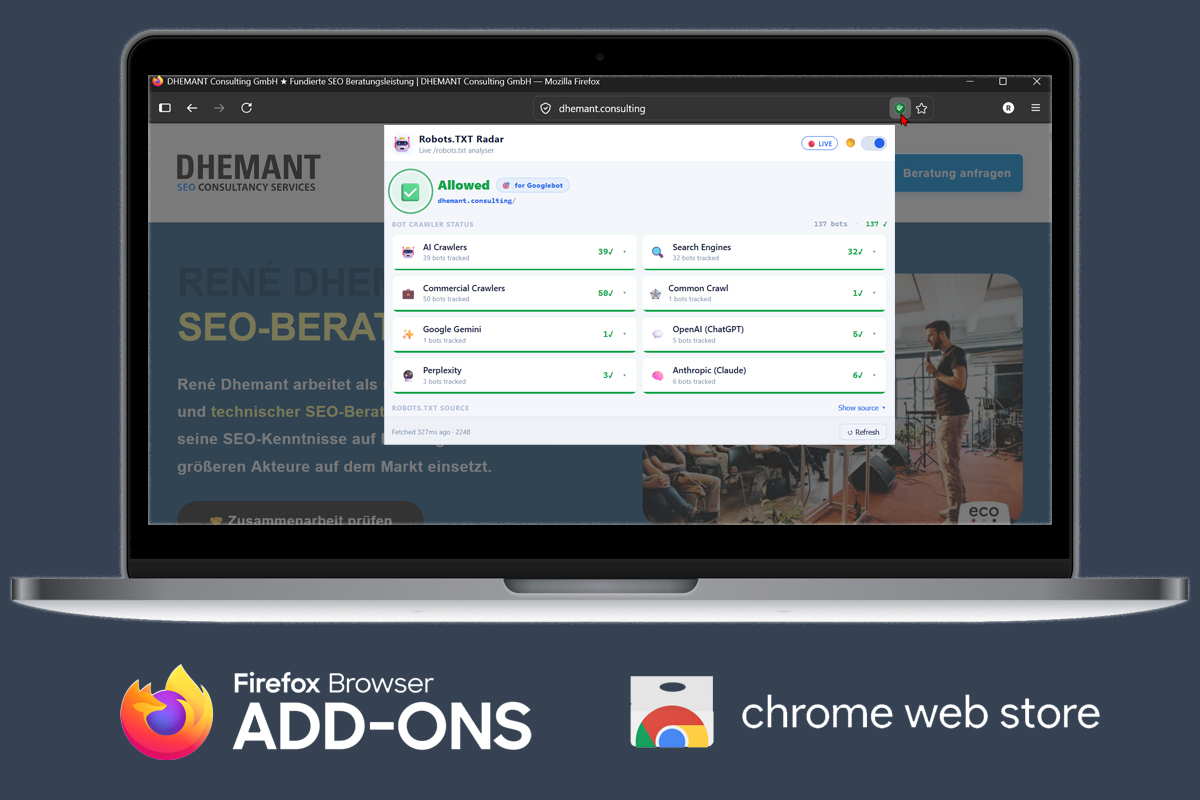
Die kostenlose Browser-Erweiterung für Firefox und Chrome analysiert auf jeder Website die robots.txt-Datei und zeigt Ihnen sofort an 🟥🟩, welche Suchmaschinen, KI-Crawler und kommerziellen Bots dort Zugriff haben.

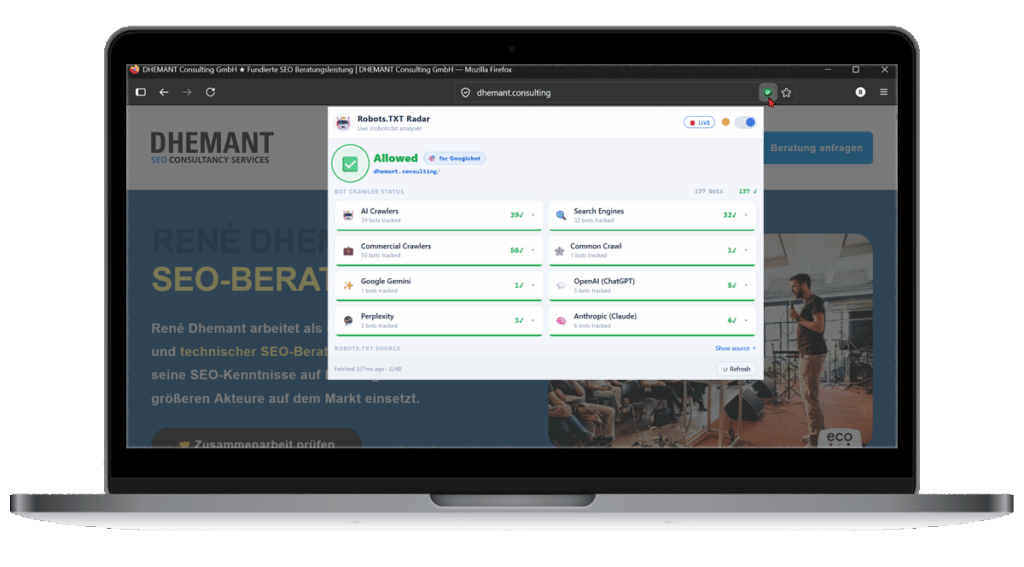
Wer darf die aktuell von Ihnen besuchte URL crawlen? Robots.TXT Radar gibt Ihnen die Antwort in Echtzeit.
Inklusive der neuen Content-Signals-Direktive von Cloudflare, mit der Website-Betreiber explizit festlegen können, ob ihre Inhalte für KI-Training, KI-Antworten oder klassische Suchmaschinen verwendet werden dürfen.
Inhaltsverzeichnis
Keine Anmeldung. Keine Datenerfassung. Quelloffen. Einfach installieren und in der Browser-Leiste jederzeit sehen, wer crawlen darf. 😌
Download 📥 Plugin Robots.TXT Radar im offiziellen Plugin-Store

- Aufrufen: addons.mozilla.org
- Nach „Robots.TXT Radar“ suchen
- Auf „Zu Firefox hinzufügen“ klicken
- Das Icon erscheint automatisch in der Adressleiste

- Aufrufen: chromewebstore.google.com
- Nach „Robots.TXT Radar“ suchen
- Auf „Hinzufügen“ klicken
- Auf das Puzzleteil-Symbol oben rechts klicken und die Erweiterung in der Toolbar anpinnen
Warum ist das Plugin-Icon bei Firefox in der Adresszeile und bei Chrome nicht?
Weil Chrome diese Möglichkeit für Erweiterungen abgeschafft hat. Firefox bietet sie weiterhin an.
In Firefox sehen Sie das Icon automatisch in der Adresszeile, sobald eine HTTP/HTTPS-Seite geladen ist. In Chrome müssen Sie das Icon einmalig per Klick auf das Puzzleteil-Symbol 🧩 oben rechts an die Toolbar anpinnen, danach bleibt es dort dauerhaft sichtbar.
Umfang 📦 der Browser-Erweiterung Robots.TXT Radar
- 137 Bot-Auswertungen pro Seitenaufruf über 8 thematisch sortierte Cluster (Suchmaschinen, KI-Crawler, kommerzielle Crawler, OpenAI, Anthropic, Perplexity, Common Crawl, Google Gemini)
- Cloudflare Content Signals werden vollständig unterstützt und visuell als farbcodierte Pills dargestellt
- RFC 9309 konform: Der Parser implementiert exakt die offizielle Google-Spezifikation
- 100% datenschutzfreundlich: Keine Telemetrie, keine Analyse-Dienste, keine externen Server, keine Datenerfassung
- Open Source: vollständig einsehbarer Quellcode, MIT-Lizenz
- Verfügbar für beide großen Browser: Firefox (Icon direkt in der Adressleiste) und Chrome (Icon in der Toolbar)
- Kostenlos, keine Premium-Variante, kein Account erforderlich
- Darkmode & Light-Mode Theme
- Bonus: Die Chrome-Erweiterung funktioniert auch in Microsoft Edge 🙂
Zielgruppe 👨🏻💻 des Browser Add-on Robots.TXT Radar
Die primäre Zielgruppe für das Browser-Add-on Robots.TXT Radar umfasst SEO-Experten und digitale Vermarkter, die Crawling-Anweisungen analysieren. Web-Entwickler, die die robots.txt-Datei während der Entwicklung und des Deployments überprüfen. Webmaster, die den Bot-Zugriff überwachen.
SEO-Fachleute: Benötigen eine schnelle Überprüfung des Indexierungsstatus von URLs direkt im Browser.
Online-Marketing-Profis: Analysieren die Zugänglichkeit von Webseiten für Suchmaschinen ohne den Einsatz externer Tools.
Webentwicklerinnen und Webentwickler: Bekommen Live-Feedback während der Entwicklung, ob die robots.txt-Konfiguration korrekt arbeitet.
Website-Betreiber ohne technischen Hintergrund: Erhalten Verständlich aufbereitete Information, warum bestimmte Seiten bei Google möglicherweise nicht erscheinen.
Content Creator und Blogger: Haben eine schnelle Bestätigung, ob Suchmaschinen einen neuen Artikel crawlen dürfen.
Journalistinnen und Researcher: Verfügen über transparente Einsicht in die Crawler-Erlaubnisse einer Website, inklusive Cloudflares neuer Content-Signals.
Technische Kurzbeschreibung 🧩 des Robots.TXT Radar Plugins
Robots.TXT Radar ist ein kostenloses Open-Source-Projekt unter MIT-Lizenz. Verfügbar für Mozilla Firefox und Google Chrome in den offiziellen Plugin-Stores.
Robots.TXT Radar ist eine WebExtension für Firefox (Manifest V2) und Chrome (Manifest V3). Bei jeder Navigation lädt die Erweiterung im Hintergrund die robots.txt der aktuellen Domain, parst sie nach RFC 9309 und wertet sie gegen den aktuellen URL-Pfad aus.
Die Analyse umfasst pro Seitenaufruf 137 Bot-Auswertungen, gegliedert in 8 thematische Cluster. Für jeden Bot werden explizite Gruppen und Wildcard-Fallback-Regeln korrekt nach Spezifikation kombiniert (längster Pfad gewinnt, Allow schlägt Disallow bei Pfadgleichheit, Gruppen-Merging bei doppelten User-Agent-Einträgen, regelkonforme Auswertung der Wildcard-Zeichen * und $).
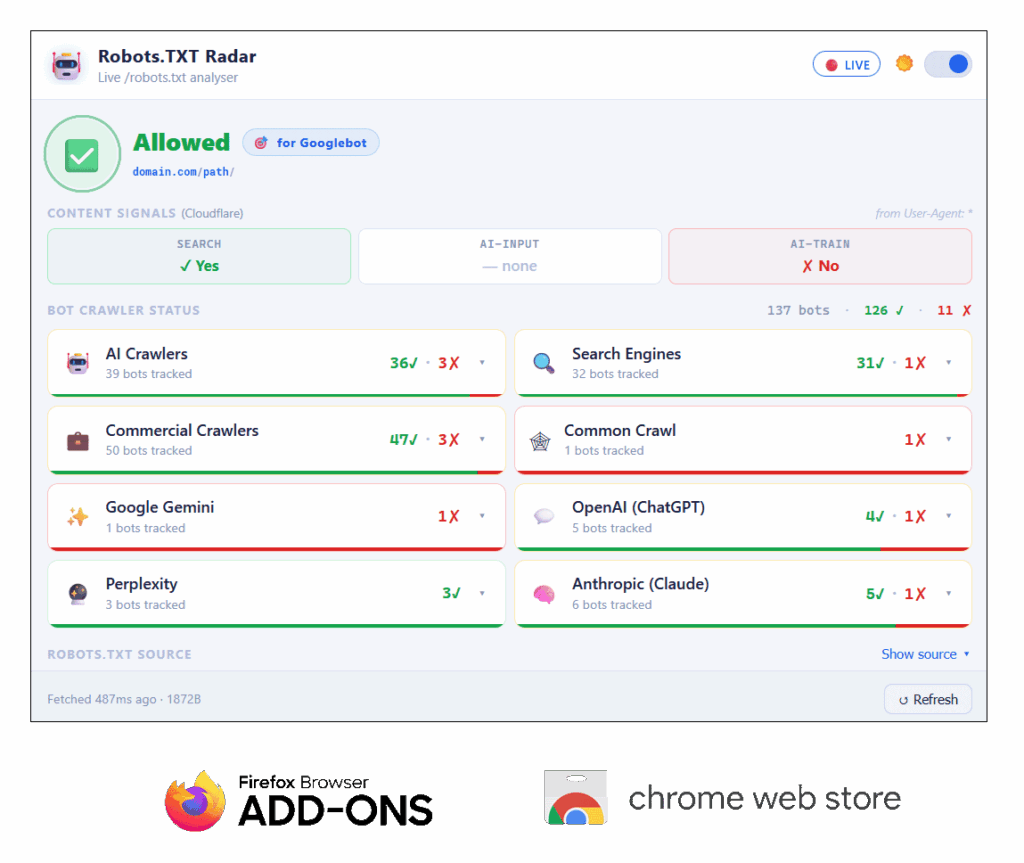
Zusätzlich erkennt der Parser die Content-Signal-Direktive nach der von Cloudflare publizierten Syntax und stellt die drei definierten Signal-Werte (search, ai-input, ai-train) als farbcodierte Pills im Popup dar. Die Signal-Auswertung folgt derselben Präzedenz wie Allow/Disallow.
Das Icon in der Browser-Leiste wird per OffscreenCanvas frame-by-frame als animierte Radar-Welle gezeichnet, ohne externe Bilder. Pro Domain wird die robots.txt für eine Stunde in der Session-Storage zwischengespeichert. Die einzige Netzwerkanfrage ist der GET-Aufruf auf /robots.txt der besuchten Domain. Es gibt keine externen Abhängigkeiten, kein eval(), kein innerHTML, keine Remote-Code-Ausführung.
Detaillierte Feature-Liste 🗐 von Robots.TXT Radar (Firefox & Chrome/Edge)
Live-Analyse mit farbcodiertem Browser-Icon
Das Browser-Add-on Robots.TXT Radar führt eine Live-Analyse der robots.txt-Datei jeder besuchten Webseite durch und zeigt den Status über ein farbcodiertes Icon in der Browser-Leiste an. Die Farben repräsentieren den Indexierungsstatus:
- Grünes Häkchen: Googlebot darf diese Seite crawlen
- Rotes X: Googlebot ist für diese Seite gesperrt
- Türkis: Keine robots.txt vorhanden, alle Bots erlaubt
- Grau-neutral: Nicht anwendbar (z.B. Chrome-interne Seiten oder Cloudflare-geschützte Stores)
- Animierte Radar-Welle: Analyse läuft
Detail-Popup mit Klick auf das Icon
- Hauptverdikt mit dem konkreten Pfadregel, die für Googlebot greift
- Cloudflare Content Signals: drei Pills für search, ai-input, ai-train
- 8 Bot-Cluster als zweispaltige Kacheln mit Allow/Disallow-Zählern und Verhältnisbalken
- Detail-Ansicht pro Cluster: Klick auf eine Kachel zeigt die genauen blockierten Bots inklusive der zugehörigen robots.txt-Regel
- Syntaxhervorhebung im Quelltext-Viewer für User-Agent, Allow, Disallow, Sitemap und Content-Signal
- Dark Mode und Light Mode mit gespeicherter Präferenz
Die 8 Bot-Cluster im Detail
- 🤖 AI Crawlers: 39 KI-Crawler (GPTBot, ClaudeBot, Perplexity, Gemini, GoogleOther, DeepSeek, Mistral, Grok und mehr)
- 🔍 Search Engines: 32 klassische Suchmaschinen (Googlebot-Familie, Bing, Baidu, Yandex, Apple, DuckDuckGo, Mojeek, Yahoo und mehr)
- 💼 Commercial Crawlers: 50 kommerzielle und spezialisierte Crawler (Amazonbot, Bytespider, Diffbot, Firecrawl, Scrapy und mehr)
- 🕸 Common Crawl: CCBot
- ✨ Google Gemini: Google-Extended (Googles KI-Trainingscorpus)
- 💬 OpenAI (ChatGPT): GPTBot, OAI-SearchBot, ChatGPT-User-Varianten
- 🔮 Perplexity: PerplexityBot, Perplexity-User
- 🧠 Anthropic (Claude): ClaudeBot, Claude-Web, Claude-User, Claude-SearchBot, Claude-Code, Anthropic-AI
Cloudflare Content Signals
Das Add-on unterstützt die Cloudflare-Content-Signal-Direktive vollständig, die Webmastern erlaubt, die Authentizität und Nutzung von Inhalten durch Crawler zu kennzeichnen. Die Analyse wird im Popup durch farbcodierte Pills dargestellt, die den Status der content-crawler und content-source Direktiven anzeigen.
- search: Erlaubnis für Such-Indexierung (explizit ohne KI-Zusammenfassungen)
- ai-input: Erlaubnis für KI-Echtzeit-Antworten (Retrieval Augmented Generation, AI Overviews)
- ai-train: Erlaubnis für KI-Modell-Training
Jeder Wert wird als grünes Yes, rotes No oder graues „keine Präferenz“ dargestellt. Bei mehreren Bot-spezifischen Signal-Sets wird das im Header der Sektion vermerkt.
Performance und Datenschutz
- 6 Sekunden Timeout pro robots.txt-Abruf verhindert Hänger
- 10 Sekunden Watchdog im Popup sorgt dafür, dass das Interface niemals dauerhaft im Scanning-Modus stehen bleibt
- Pro Domain 1 Stunde Cache in chrome.storage.session bzw. browser.storage.session
- Restricted-Host-Liste: Chrome Web Store, Google Account, AMO und vergleichbare Domains werden stillschweigend übersprungen, um irrelevante CORS-Fehler zu vermeiden
- Keine Telemetrie, keine Analytics, keine externen Skripte, keine CDN-Importe
- Inkognito/Privater Modus wird unterstützt
Anleitung 📝 zum Erstellen einer guten robots.txt-Datei
Audisto bietet einen umfassenden Leitfaden zur korrekten Erstellung und Optimierung einer robots.txt-Datei, die den Zugriff von Web-Crawlern auf Internetseiten steuert.

Unterschiedliche Protokoll-Standards und Interpretationsweisen von Suchmaschinen können zu technischen Komplikationen oder Traffic-Verlusten führen.
Audisto warnt vor häufigen Fehlern, wie etwa der falschen Nutzung von Leerzeilen, Kommentaren oder Sonderzeichen, die das Auslesen der Anweisungen behindern.
Eine präzise Konfiguration der robots.txt-Datei ist entscheidend ist, um die Sichtbarkeit und Indexierung einer Website gezielt zu steuern.
Der Audisto Crawler und das dedizierte Audisto Monitoring eigenen sich perfekt zur Analyse und Überwachung sehr großer Webseiten.
Versionshistorie / Changelog
v4.4.0 (Firefox) / v2.4.0 (Chrome): GUI-Überarbeitung
- Popup-Breite auf 720 Pixel verdoppelt, mit zweispaltigem Cluster-Grid
- Alle Cluster-Karten sind standardmäßig eingeklappt für eine aufgeräumte Übersicht
- Neues „für Googlebot“-Badge im Hero-Bereich verdeutlicht, auf welchen Bot sich die Hauptanzeige bezieht
- Quelltext-Viewer um 47 Prozent höher (220 Pixel) für besseres Lesen langer robots.txt-Dateien
v4.3.1 (Firefox) / v2.3.1 (Chrome): Content Signals Sichtbarkeitsfix
- Content-Signal-Sektion wurde korrekt geparst, aber durch einen fehlenden Funktionsaufruf in v4.3.0 / v2.3.0 nicht im Popup gerendert. Behoben.
v4.3.0 (Firefox) / v2.3.0 (Chrome): Perplexity- und Anthropic-Cluster
- Neuer dedizierter Cluster „Perplexity“ mit PerplexityBot, Perplexity-User, Perplexity-User-1-0
- Neuer dedizierter Cluster „Anthropic (Claude)“ mit ClaudeBot, Claude-Web, Claude-User, Claude-SearchBot, Claude-Code, Anthropic-AI
- Insgesamt jetzt 8 Cluster mit 137 Bot-Auswertungen
v4.2.0 (Firefox) / v2.2.0 (Chrome): OpenAI-Cluster
- Neuer dedizierter Cluster „OpenAI (ChatGPT)“ mit allen fünf offiziellen OpenAI-User-Agents (GPTBot, OAI-SearchBot, ChatGPT-Operator, ChatGPT-User, ChatGPT-User-2-0)
- Gleiche Doppel-Zugehörigkeit wie bei Google Gemini und Common Crawl: Bots bleiben zusätzlich im allgemeinen AI-Crawler-Cluster
v4.1.0 (Firefox) / v2.1.0 (Chrome): Cloudflare Content Signals
- Vollständige Unterstützung der neuen Content-Signal-Direktive (Cloudflare, 2025)
- Drei farbcodierte Pills für search, ai-input, ai-train direkt im Popup
- Tooltip-Erklärungen zu jedem Signal
- Pro-Bot Signal-Auswertung mit derselben Präzedenz wie Allow/Disallow (explizite Gruppe schlägt Wildcard-Fallback)
- Content-Signal-Zeilen werden im Quelltext-Viewer farblich hervorgehoben
- Sektion blendet sich automatisch aus, wenn die Direktive auf einer Site nicht verwendet wird
v4.0.0 (Firefox) / v2.0.0 (Chrome): Bot-Clustering und UI-Überarbeitung
- Cluster-basierte Analyse über zunächst 5 Kategorien (AI, Search, Commercial, Common Crawl, Gemini)
- Pro Cluster-Karte: Allow/Disallow-Zähler und Verhältnisbalken
- Detail-Ansicht pro Cluster mit Klick zeigt blockierte Bots inklusive der zugehörigen Regel
- Hero-Bereich zeigt das Googlebot-Verdikt inklusive der greifenden Pfadregel
v3.x (Firefox) / v1.x (Chrome): Architektur und Stabilität
- Umbenennung von „Robots Radar“ zu „Robots.TXT Radar“ für klareren Kontext
- Inline-Parser in beiden Kontexten (Popup und Background) für höhere Zuverlässigkeit
- 6-Sekunden-Timeout für robots.txt-Abrufe
- 10-Sekunden-Watchdog im Popup verhindert dauerhaftes „Scanning“
- Restricted-Host-Liste für Cloudflare-geschützte Domains
- Verbose Console-Logging zur einfacheren Fehlerdiagnose
v1.0 / v2.0 (Firefox): Erstveröffentlichung
- RFC-9309-konformer Parser für Allow, Disallow, Wildcards und Spezifitäts-Regel
- Vier priorisierte Target-Bots: Googlebot, Bingbot, CCBot, Google-Extended
- Animiertes Radar-Icon in der Adressleiste
- Dark Mode und Light Mode mit gespeicherter Präferenz
- Pro-Domain Caching für eine Stunde

