

Dieses kostenfreie Tool führt eine simultane Zero-Shot-Abfrage über die API von 7 führenden KI-Modellen durch. Es misst die historische Markenautorität und die Präsenz Ihres digitalen Fußabdrucks im reinen Systemwissen der Künstlichen Intelligenz.


Testen Sie, ob Ihr Unternehmen als Entität im parametrischen Wissen führender Large Language Models (LLMs) verankert ist.
Inhaltsverzeichnis
Analyse des LLM-Basiswissens 🧠 Ihrer Marke
Eine Analyse des LLM-Basiswissens für eine Marke prüft die Verankerung einer Marken-Entität im parametrischen Wissen von Foundation-Modellen. Sie quantifiziert, ob ein LLM die Marke ohne externe Datenquellen (wie RAG) aus seinen eigenen Basisgewichten statistisch reproduzieren kann.
Die kostenfreie Analyse ist komplett unabhängig von Grounding oder Websuchen. Je höher die Erkennungsrate hier ist, desto tiefer ist Ihre Marke im KI-Ökosystem verankert. Training-Sichtbarkeit ist im Wesentlichen strukturiertes Entity-SEO mit langem Horizont.
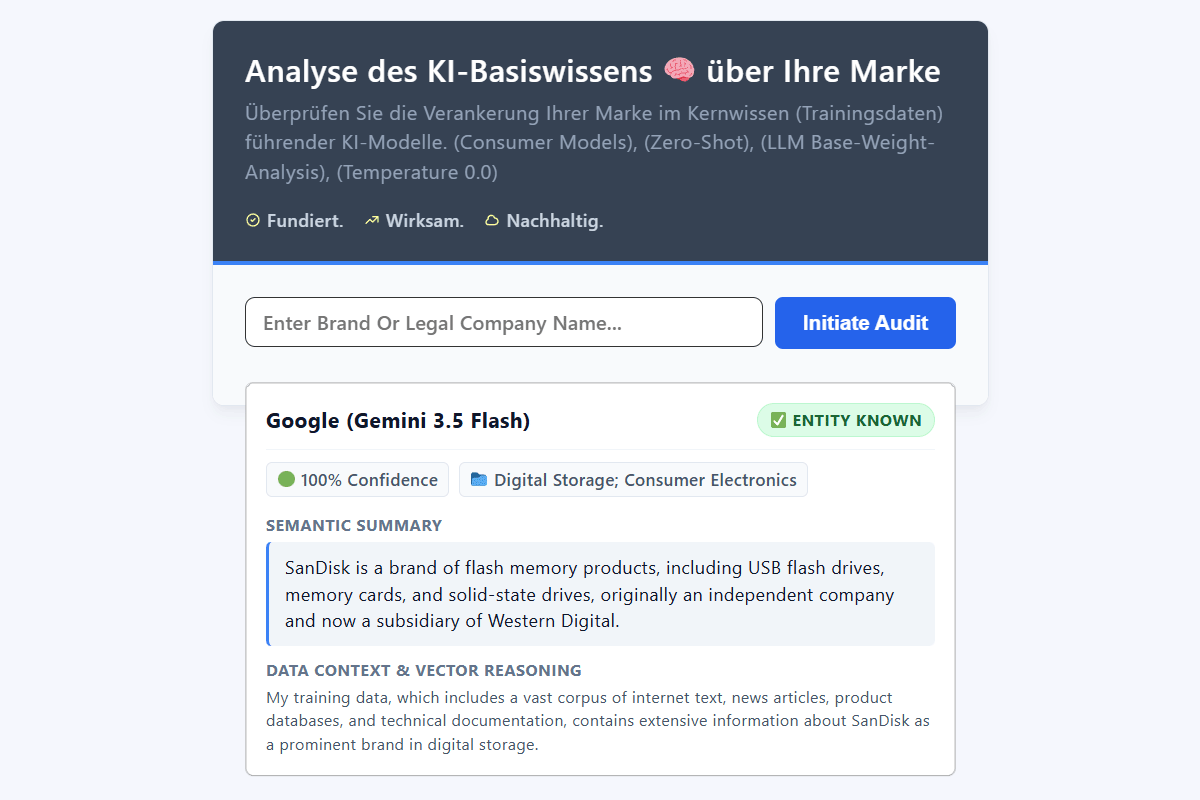
Analyse des KI-Basiswissens 🧠 über Ihre Marke
Überprüfen Sie die Verankerung Ihrer Marke im Kernwissen (Trainingsdaten) führender KI-Modelle. (Consumer Models), (Zero-Shot), (LLM Base-Weight-Analysis), (Temperature 0.0)
Warum die Entitäten-Prüfung für Marken essenziell ist
Suchmaschinen erhalten zunehmend Komponenten von Antwortmaschinen (AI Overviews, SGE). LLMs rufen keine URLs ab, sondern synthetisieren Antworten aus statistisch erlernten Mustern.
Was wir im SEO als Entität bezeichnen, muss im Modell als robuste parametrische Repräsentation existieren. Ist diese Repräsentation in Bezug auf Ihre Marke zu schwach, fallen Sie durch das Raster der Wahrscheinlichkeitsberechnung.
Ein Sprachmodell (GPT) kennt keine Marken. Es baut während des Pre-Trainings statistische Repräsentationen von Entitäten auf und berechnet lediglich Wahrscheinlichkeiten (Token-Predictor).
Wenn der Name Ihres Unternehmens in den Trainingsdaten kein starkes statistisches Gewicht aufbauen konnte, tauchen Sie in ungestützten KI-Antworten schlichtweg nicht auf. Eine hohe URL-Sichtbarkeit in klassischen SERPs garantiert heute nicht mehr, dass Ihre Marke auch in den Basisgewichten generativer KI präsent ist.
Dieser kostenfreie KI Entitäts-Check der DHEMANT Consulting GmbH versucht Ihre Markenautorität in den Trainingsdaten von weit verbreiteten Sprachmodellen (Consumer Models) messbarer zu machen. Die Analyse zeigt auf, ob Ihre Marke eine ausreichende Präsenz in denjenigen Webquellen aufgebaut hat, um einen bleibenden Abdruck im Trainingskorpus der großen KI-Anbieter zu hinterlassen.
Markenpräsenz in LLM-generierten Antworten ist im Wesentlichen ein Entitätssalienz-Problem.
Im isolierten Zero-Shot-Kontext entscheidet die statistische Dichte der Basisgewichte, im RAG-Kontext entscheidet die Chunk-Relevanz. Beide Ebenen lassen sich aktiv beeinflussen. Dies gelingt über konsistente Entitätssignale im Web (klassisches Entity-SEO) für die Trainingsgewichte sowie über strukturierte, chunkfreundliche Inhalte für die Retrieval-Schicht.
Gewinnen Sie handfeste und datenbasierte SEO-Handlungsempfehlungen, anstatt sich auf Ihr Bauchgefühl verlassen zu müssen (oder auf das lediglich angelesene Buchwissen Dritter).
Markenbekanntheit wird so von einem abstrakten Marketing-Begriff zu einem messbaren Konstrukt auf Vektorebene.
LLMs haben keine Einsicht in ihr eigenes parametrisches Wissen
Ein LLM ist keine relationale Datenbank, die eine Suchanfrage (SQL) ausführt und bei null Treffern ein NULL zurückgibt. 💡 Es ist ein Next-Token-Predictor. Es „weiß“ nicht, was es weiß.
Wenn Sie fragen: 🗣️ „Kennst du Entität X?“, greift sofort die Bestätigungstendenz (Sycophancy): Das Modell berechnet Wahrscheinlichkeiten für Wörter, die mit X zu tun haben, und fängt möglicherweise an zu halluzinieren, um den Nutzer zufriedenzustellen.
Aber ich habe das Tool KI Entitäts-Check Ihrer Marke durch drei ineinandergreifende, technische Prompt-Engineering-Ebenen so nah an die Wahrscheinlichkeit herangeführt, wie es die aktuelle Architektur zulässt.
Logprobs (Logarithmic Probabilities) werden aktuell nicht genutzt. Details entnehmen Sie dem Einblick in die Architektur 👇
Einblick in die Architektur des Tools KI Entitäts-Check 👀
Argmax-Sampling (temperature: 0.0)
Indem ich die Temperatur auf exakt null setze, deaktiviere ich das probabilistische Sampling der Modelle. Das LLM wählt für den nächsten Token nicht mehr aus einer gewichteten Liste möglicher Wörter aus, sondern ist gezwungen, immer den mathematisch wahrscheinlichsten Token zu wählen. Das reduziert die „Kreativität“ (und damit die Halluzinationsrate) drastisch.
Umkehrung der Sycophancy (Negative Constraints)
Normalerweise wollen LLMs eine gestellte Frage aufgrund ihrer Ausrichtung positiv beantworten. Ich konditioniere das Kontextfenster (Context Window) im System-Prompt massiv durch Negative Constraints: DEFAULT ASSUMPTION: The entity DOES NOT EXIST. und Hallucinating is a critical failure. Ich verschiebe die „Straf-Gewichtung“ im Prompt. Das Modell wird instruiert, dass eine erfundene Antwort ein kritischer Systemfehler ist, während ein Eingeständnis von Unwissenheit das gewünschte, sichere Verhalten darstellt.
Zwang zu Chain-of-Thought (CoT) im JSON-Schema
Das ist der wichtigste, oft übersehene Hebel in unserem aktuellen Code. Ich fordere zuerst „reasoning“ und erst danach den logischen Schalter „known„. LLMs können nicht „vorausdenken“. Würde ich zuerst „known“: true abfragen, müsste das Modell danach eine Begründung erfinden, um seine eigene Behauptung zu stützen. Indem ich zuerst das „reasoning“ erzwinge, muss das Modell sein Wissen (die Vektoren) im Ausgabefenster ausbreiten. Findet es in seinen Vektoren keine belastbaren Fakten für die Begründung, kippt die Wahrscheinlichkeit für den anschließenden Booleschen Wert mathematisch fast unausweichlich auf „known“: false.
Wie man es noch deterministischer machen könnte (Ausblick)
Die einzige Möglichkeit, dieses System auf ein absolutes, unverwundbares deterministisches Level zu heben, wäre eine Verifizierungs-Schleife (Honeypot/Grounding). Der Nutzer müsste im Frontend nicht nur den Namen eingeben, sondern z. B. zwingend auch die korrekte Branche oder das Gründungsland auswählen. Das Backend vergleicht dann den Output des LLMs mit der harten Eingabe des Nutzers. Stimmt die vom LLM generierte Branche nicht mit der Vorgabe überein, überschreibt unser PHP-Code das Ergebnis deterministisch auf Entity Unknown.
Logprobs (Logarithmic Probabilities) [Der Goldstandard]
Die Logprobs (Logarithmic Probabilities) hingegen geben uns den direkten Blick in das „Gehirn“ (den Softmax-Layer) der KI. Sie zeigen die nackte, mathematische Wahrscheinlichkeit für exakt dieses eine Wort. Wenn ich die Logprobs auslese, könnte ich genau sehen, mit welcher mathematischen Sicherheit das Modell beim Key „known“ das Token true gegenüber dem Token false abgewogen hat. Wenn true nur eine Wahrscheinlichkeit von 52 % hat, weiß ich algorithmisch absolut sicher: Die KI rät und ich könnte das Ergebnis serverseitig deterministisch auf „Unknown“ überschreiben.
Warum nutze ich Logprobs (noch) nicht?
Der Grund ist reiner Pragmatismus aufgrund von API-Fragmentierung. Ich feuer aus einem einzigen WordPress-Snippet auf 7 völlig verschiedene Architekturen: OpenAI & Meta (via Groq) / xAI: Hier wäre es ein Traum. Ich könnte einfach „logprobs“: true in den Request-Body packen und bekäme wunderschöne, saubere Wahrscheinlichkeitswerte für jedes Token zurück. Anthropic (Claude): Anthropic ist notorisch restriktiv und liefert über die Standard-Messages-API historisch keine sauberen Token-Logprobs aus. Sie kapseln die Modelle stark ab. Google Gemini: Die Standard-API (generateContent) handhabt Metadaten und Probabilities anders als der de-facto OpenAI-Standard. Perplexity: Da es sich um eine RAG-Pipeline (Retrieval-Augmented Generation) handelt, sind klassische Next-Token-Logprobs für die finale Antwort oft verfälscht oder über die API gar nicht erst zugänglich, da die Suche das Generative überlagert.
Wie das Tool KI Entitäts-Check technisch arbeitet
Ein LLM erkennt Marken probabilistisch, kontextabhängig und signalgetrieben. Nicht als bewusstes Wissen, sondern als gelernte statistische Struktur.
Der KI Entitäts-Check ermittelt die Verankerung einer Entität im parametrischen Wissen von LLMs durch einen mehrstufigen Prozess:
- Verhaltensbasierte Abfrage des parametrischen Wissens (Base Weights): Indirekte Inferenz über das im Pre-Training gebildete, parametrische Wissen des Modells zur Entitätserkennung
- Zero-Shot Prompting mit negativen Constraints: Einsatz einer Abfragemethode, die Halluzinationen minimiert und die Zuverlässigkeit der Entitätserkennung durch gezielte Falschinformationen testet
Um valide und reproduzierbare Daten zu erhalten, nutzt das Tool KI Entitäts-Check einen strikten technischen Rahmen und fragt die Modelle über ihre direkten API-Endpunkte ab. Ich schließe die üblichen Chat-Interfaces (wie ChatGPT oder die Gemini-Weboberfläche) bewusst aus, um unverfälschte Rohdaten zu erhalten.
Abfrage der Basisgewichte (Base Weights)
Die Abfrage der Basisgewichte (Base Weights) eines LLM zielt auf das im initialen Pre-Training erlernte, fixierte parametrische Wissen ab. Basisgewichte sind die mathematischen Parameter, die das Kernwissen des Modells ohne externe Datenquellen darstellen.
Ich teste hier ausschließlich das „Langzeitgedächtnis“ der Modelle. Basisgewichte sind die fixierten mathematischen Parameter, die ein LLM während seines initialen Pre-Trainings gebildet hat. Die Modelle werden ohne Tool-Zugang abgefragt. Kein externer Datenzugriff ist möglich (mit Ausnahme von Perplexity). Das Modell muss die Entität (Ihre Marke oder Person) also nativ „kennen“.
Zero-Shot Prompting mit negativen Constraints
Zero-Shot Prompting mit negativen Constraints ist eine Abfragemethode, die zwei Techniken kombiniert, um die Zuverlässigkeit der Modellerkennung zu testen: Zero-Shot Prompting & Negative Constraints.
Die Tool-Abfrage erfolgt als „Zero-Shot“. Das LLM erhält im Prompt keinerlei Kontext oder Beispiele, wie etwa: „Dies ist ein deutsches Softwareunternehmen„. Gleichzeitig nutze ich harte negative Constraints (Restriktionen) im System-Prompt. Den Modellen wird explizit befohlen, die Existenz der Entität zu verneinen, sofern keine hohe Datendichte vorliegt.
Die analysierten KI-Modelle im Überblick
Der KI Entitäts-Check analysiert parallel 7 unterschiedliche Foundation-Modelle. Die Auswahl konzentriert sich auf Modelle, die primär ihr parametrisches Wissen (Basisgewichte) nutzen. Diese Modelle arbeiten isoliert und greifen zur Beantwortung von Anfragen ausschließlich auf ihren internen, trainierten Textkorpus zu. Eine positive Entitätserkennung („Entity Known„) durch diese Modelle deutet auf eine signifikante Verankerung der Marke in den Trainingsdaten hin.
- OpenAI (GPT-4o mini)
- Anthropic (Claude Sonnet)
- Google (Gemini 3.5 Flash)
- Microsoft Azure (GPT-4o mini via Azure-Infrastruktur)
- Meta (Llama 3.1 8B via Groq)
- xAI (Grok 4.3)
Modelle mit Fokus auf RAG / Live-Websuche:
- Perplexity (Sonar): Perplexity nimmt hier eine architektonische Sonderrolle ein. Es ist darauf trainiert, das Live-Internet zu durchsuchen, bevor es eine Antwort generiert. Ein Treffer bei Perplexity spiegelt somit nicht zwingend das historische Basiswissen wider, sondern beweist einen exzellenten, aktiven SEO-Fußabdruck in Echtzeit.
Interpretation der Ergebnisse
Die Interpretation der Ergebnisse basiert auf drei zentralen Metriken, die für jedes abgefragte Modell bereitgestellt werden:
- Entity Known (Status): Ein binärer Wert (Ja/Nein), der angibt, ob das Modell die Entität auf Basis seines internen Wissens erkennt.
- Confidence Score (Sicherheit): Ein numerischer Wert, der selbsteingeschätzten (self-reported) Konfidenz des Modells. Wichtig: Da keine Logprobs aus der Softmax-Schicht ausgelesen werden, dient dieser Wert als UX-Orientierungshilfe. Er spiegelt wider, wie stark das statistische Token-Muster ist, mit dem das Modell seine eigene Aussage textlich validiert.
- Data Context & Vector Reasoning (Beschreibung): Eine vom Modell generierte Kurzbeschreibung der Entität, die zur qualitativen Überprüfung der abgerufenen Trainingsdaten (Vektor-Distanzen) dient.
Die Kombination dieser Metriken ermöglicht eine Einschätzung der Bekanntheit und korrekten Repräsentation einer Entität im Basiswissen des jeweiligen KI-Modells.
Hinweis zum Caching ⚡: Zur Schonung der API-Ressourcen und für eine verzögerungsfreie Auslieferung bei wiederkehrenden Abfragen werden die Resultate dieses KI Entitäts-Check für exakt 30 Tage serverbasiert zwischengespeichert (Cache). Über die Funktion „Copy Share Link“ können Sie den generierten Audit-Report inklusive eindeutiger Audit-ID jederzeit mit Ihrem Team teilen.
René Dhemant unterstützt B2B-Unternehmen primär dann, wenn sich klassische SEO-Erfolge nicht in KI-Antworten übersetzen oder Zweifel an der Zukunftsfähigkeit laufender Agentur-Maßnahmen bestehen.
Seine Hilfe als strategischer Berater zielt darauf ab, teure Keyword-Jagd in echtes Entity-SEO und eine messbare Verankerung in den Basisgewichten der LLMs zu verwandeln.

FAQ Tool KI Entitäts-Check
Warum ist es wichtig, dass meine Marke im parametrischen Wissen der KI repräsentiert ist?
Fehlt Ihrer Marke die nötige Datendichte in den Trainingsdaten, werden Sie in KI-generierten Zusammenfassungen (wie AI Overviews) nicht erwähnt. Ihre Sichtbarkeit hängt nicht mehr nur von Links ab, sondern von der Verankerung als Entität im KI-Wissen.
Welche spezifischen Metriken liefert der Audit-Report zur Bewertung der Markenautorität?
Die Interpretation der organischen Sichtbarkeit im parametrischen LLM-Basiswissen basiert auf drei zentralen Metriken: dem binären Wert „Entity Known“ (Status), dem numerischen „Confidence Score“ (Sicherheit) und der Modell-generierten Kurzbeschreibung „Data Context & Vector Reasoning“. Das generierte Audit enthält zudem eine eindeutige Audit-ID und kann jederzeit über die Funktion „Copy Share Link“ im Team geteilt werden.
Was ist der Unterschied, ob eine KI meine Marke aus Trainingsdaten oder per Websuche kennt?
Kenntnis aus Trainingsdaten bedeutet, Ihre Marke ist Teil des KI-Grundwissens, was hohe Autorität signalisiert. Eine Websuche (RAG) ist nur eine Momentaufnahme Ihrer aktuellen SEO-Stärke. Echte Verankerung im Basiswissen ist nachhaltiger für die Sichtbarkeit in KI-generierten Antworten.
Wie stellt das Tool sicher, dass die KI nicht einfach nur rät oder halluziniert?
Ich nutze drei technische Hebel: Die Kreativität der KI wird durch „Temperature: 0“ deaktiviert. Zudem wird dem Modell befohlen, standardmäßig von einer Nicht-Existenz auszugehen. Zuletzt erzwinge ich eine logische Begründung, bevor es den Status „bekannt“ oder „unbekannt“ ausgeben darf.
Wie reproduzierbar sind die Ergebnisse über verschiedene Modelle hinweg, oder schwankt die Entitäts-Erkennung je nach Anbieter stark?
Die Reproduzierbarkeit innerhalb eines Modells ist durch Argmax-Sampling hoch: Gleicher Input liefert ein reproduzierbares Ergebnis. Zwischen den Modellen variiert die Erkennung, weil jedes Modell auf einem anderen Trainingskorpus basiert. Genau diese Varianz ist der Kern der Analyse. Ein Ergebnis über sieben Modelle hinweg ist kein simpler Durchschnitt, sondern eine Landkarte. Sie zeigt präzise, in welchen Teilen des KI-Ökosystems eine Marke bereits parametrisch verankert ist und wo nicht.
Warum wird ein Treffer bei Perplexity anders bewertet als bei den anderen KI-Modellen?
Perplexity ist darauf spezialisiert, das Live-Internet zu durchsuchen (RAG), bevor es antwortet. Ein Treffer dort zeigt exzellente aktuelle SEO-Arbeit. Die anderen Modelle nutzen ihr internes Basiswissen, ein Treffer dort beweist eine tiefere, historische Verankerung Ihrer Marke in den KI-Trainingsdaten.
Warum erkennt Perplexity meine Marke fehlerfrei, während GPT-4o und Claude sie nicht kennen?
Das liegt an der unterschiedlichen Systemarchitektur. GPT-4o, Claude, Gemini, Llama und Grok zwingen wir in diesem Test dazu, ausschließlich auf ihr parametrisches Gedächtnis (die eingefrorenen Basisgewichte) zuzugreifen. Perplexity (Sonar) hingegen ist als RAG-Pipeline (Retrieval-Augmented Generation) konzipiert und durchsucht vor der Antwortgebung zwingend das Live-Internet. Ein Treffer bei Perplexity beweist einen starken, aktuellen SEO-Fußabdruck in Echtzeit, auch wenn die Marke noch nicht tief in den historischen Trainingsdaten der anderen Foundation-Modelle verankert ist.
Mein Unternehmen wurde nicht von allen KI-Modellen erkannt, was bedeutet das?
Das ist normal, da jedes Modell auf unterschiedlichen Daten trainiert wurde. Eine uneinheitliche Erkennung zeigt, in welchen Teilen des „KI-Ökosystems“ Ihre Marke bereits verankert ist und wo noch Potenzial für gezielte PR- und Content-Maßnahmen besteht, um den digitalen Fußabdruck zu stärken.
Wie verhindert die Tool-Architektur durch Prompt-Engineering KI-Halluzinationen (Sycophancy)?
Der KI Entitäts-Check nutzt Argmax-Sampling mit einer Temperature von exakt 0.0, um probabilistisches Sampling zu deaktivieren und das mathematisch wahrscheinlichste Token zu erzwingen. Zusätzlich kombiniert das System Negative Constraints im System-Prompt („DEFAULT ASSUMPTION: The entity DOES NOT EXIST“) mit einem strengen Zwang zu Chain-of-Thought (CoT) im JSON-Schema, welches das „reasoning“ zwingend vor dem Booleschen Schalter „known“ abfragt.
Warum verzichtet das Tool bei der Abfrage der Base Weights auf Logprobs (Logarithmic Probabilities)?
Obwohl Logprobs (Logarithmic Probabilities) direkte Einblicke in den Softmax-Layer der KI böten, werden sie aufgrund extremer API-Fragmentierung aktuell nicht genutzt . Während OpenAI Metadaten wie „logprobs“: true im Request-Body erlaubt, kapselt Anthropic seine Modelle über die Standard-Messages-API restriktiv ab, Google Gemini verarbeitet Probabilities abweichend und bei der RAG-Pipeline von Perplexity sind klassische Next-Token-Logprobs gar nicht erst unverfälscht zugänglich.
Warum nutzt das Tool einen „Confidence Score“, wenn dieser nicht auf Logprobs basiert?
Aus strenger Machine-Learning-Sicht ist ein selbsteingeschätzter Score eines Modells (Self-Reported Confidence) kein mathematischer Beweis für die Wahrscheinlichkeit einer Aussage, sondern ein generiertes Text-Muster. In der Praxis der SEO-Analyse dient dieser Score als notwendige UX-Metrik (Orientierungshilfe). Er zeigt dem Nutzer auf einen Blick, ob das LLM bei seiner Generierung auf ein extrem dichtes Token-Cluster zurückgreifen konnte (was oft zu Ausgaben von 90–100 % führt) oder ob die Datenlage so dünn ist, dass das Modell textliche Unsicherheit signalisiert. Bei der Ausgabe „Entity Unknown“ wird dieser Score vom System automatisch ignoriert.
Ist ein solcher Check ohne die Auswertung von Logprobs nicht bloßes Raten („Snake Oil“)?
Aus der Perspektive puristischer Machine-Learning-Theorie sind Logarithmic Probabilities (Logprobs) der einzige harte, mathematische Beweis für das Wissen eines Netzes. In der Praxis der Softwareentwicklung stehen wir jedoch vor dem Problem stark fragmentierter APIs. Während OpenAI Logprobs liefert, kapseln Anbieter wie Anthropic (Claude) oder Google (Gemini) diese Metadaten in ihren Standard-Schnittstellen oft ab. Um dennoch über 7 Modelle hinweg ein hochgradig deterministisches Ergebnis zu erzielen, nutze ich ein State-of-the-Art Prompt-Engineering-Setup: Ich erzwinge Temperatur 0.0 (Argmax-Sampling), nutze harte negative Constraints und zwinge das Modell durch das JSON-Schema zu Chain-of-Thought (die KI muss erst ihre Begründung und Quellen ausgeben, bevor sie das finale True/False deklarieren darf). Das ist kein Schlangenöl, sondern angewandte Vektor-Steuerung zur Minimierung der Introspection Illusion.
Welche Kosten fallen für den Check an und wie funktioniert das Server-Caching der Audit-Reports?
Die tiefe Analyse des digitalen Fußabdrucks in KI-gestützten Antwortmaschinen ist ein völlig kostenfreies SEO-Tool der DHEMANT Consulting GmbH. Zur Schonung der begrenzten API-Ressourcen und für eine verzögerungsfreie, performante Auslieferung (⚡) werden alle Resultate für exakt 30 Tage in einem serverseitigen Cache zwischengespeichert.

